Chapter 3 Classical data and quantum computers
In this chapter discuss how to represent and load classically available data on a quantum computer. First, we describe how to represent data, which reduces to understanding the possible ways of storing information in quantum states. Then, we introduce the quantum memory model of computation, which is the model that we use to load data (which we assume to know classically) into a quantum computer. We finally look at the problem of retrieving data from a quantum computer, discussing the complexity of the problem. The main takeaway from this chapter is the understanding of the tools that are often used at the very start and very end of many quantum algorithms, which will set us up to understanding quantum algorithms in future chapters. This chapter can be tought as the study of the I/O interface of our quantum computer.
3.1 Representing data in quantum computers
We’ll begin our journey into quantum algorithms by understanding how we can represent and store data as a quantum state. Data plays a key role and is at the heart of most modern algorithms and knowing the best way to encode it on a quantum computer might pave the way for intuitions in solving problems, an essential step towards quantum advantage (as noted also in (Maria Schuld, Sinayskiy, and Petruccione 2015)).
There are various ways to achieve this task. Some are borrowed from classical computation, such as the binary encoding, which consist in representing encoding boolean strings of length \(n\) using \(n\) qubits, while some leverage quantum properties, such as the amplitude encoding, which consits in representing vectors as linear combination of computational basis. We note that some of the presented schemes depend heavily on the accuracy of the available quantum computers in manipulating quantum states (i.e. developments in metrology and sensing). For example, techniques that rely on precise amplitudes of a state will be hindered by the current noisy hardware, or incour in high overhead of the quantum error correction. Considerations on the practical feasibility of an encoding technique are out of scope for this book.
3.1.1 Binary encoding
The first method is a way to represent natural numbers on a quantum computer by using the binary expansion of the number to determine the state of a sequence of qubits. Each qubit is set to either the state \(|0\rangle\) or \(|1\rangle\), corresponding to each bit in the binary representation of the number. To represent a natural number \(x \in \mathbb{N}\) on a quantum computer, we consider the binary expansion of \(x\) as a list of \(m\) bits, and we set the state of the \(i^{th}\) qubit as the value of the \(i^{th}\) bit of \(x\):
\[\begin{equation} |x\rangle = \bigotimes_{i=0}^{m} |x_i\rangle. \tag{3.1} \end{equation}\]
When extending this definition to signed integers we can, for example, use an additional qubit to store the sign of \(x \in \mathbb{Z}\). Another possibility, is to represent signed integer using \(2\)s complement. This is actually the representation of choice for classical and quantum arithmetic (Luongo et al. 2024). For real numbers we consider that, as on classical computers, \(x \in \mathbb{R}\) can be approximated with binary representation up to a certain precision. As before, we need a bit to store the sign, some bits to store the integer part, and some bits to store the fractional part. This is more precisely stated in the following definition, which is a possible way to represent number with fixed precision.
Definition 3.1 (Fixed-point encoding of real numbers (Rebentrost, Santha, and Yang 2021)) Let \(c_1,c_2\) be positive integers, and \(a\in\{0,1\}^{c_1}\), \(b \in \{0,1\}^{c_2}\), and \(s \in \{0,1\}\) be bit strings. Define the rational number as \[\begin{equation} \mathcal{Q}(a,b,s):= (-1)^s \left(2^{c_1-1}a_{c_1}+ \dots + 2a_2 + a_1 + \frac{1}{2}b_1 + \dots + \frac{1}{2^{c_2}}b_{c_2} \right) \in [-R,R], \end{equation}\] where \(R= 2^{c_1}-2^{-c_2}\).
If \(c_1,c_2\) are clear from the context, we use the shorthand notation for a number \(z:=(a,b,s)\) and write \(\mathcal{Q}(z)\) instead of \(\mathcal{Q}(a,b,s)\). Given an \(n\)-dimensional vector \(v \in (\{0,1\}^{c_1} \times \{0,1\}^{c_2} \times \{0,1\})^n\) the notation \(\mathcal{Q}(v)\) means an \(n\)-dimensional vector whose \(j\)-th component is \(\mathcal{Q}(v_j)\), for \(j \in[n]\).
We note that the choice of \(c_1\) and \(c_2\) in definition 3.1 depends both on the problem at hand and the implemented algorithm. For the purposes of optimizing a quantum circuit, these constants can be dynamically changed. For example, if at some point of a computation we are required to work with numbers between \(0\) and \(1\), then we can neglect the \(c_1\) bits.
One of the utilities of having a definition to express numbers on a quantum computer to a fixed point precision is the analysis of numerical errors, which is essential to ensure the validity of the solution. This is often done numerically (via simulations, which we will discuss in Chapter 12 ), or during the implementation of the algorithm on real hardware. This binary encoding encompasses other kinds of encoding like \(2\)-complement encoding and a possible quantum implementation of floating point representation. Howevever, we observe that the floating point encoding has a relatively high circuital overhead and, therefore, is not a common choice. A further layer of complexity arises in understanding how to treat arithmetic operations. This is addressed in the section below.
3.1.1.1 Arithmetic model
The advantage of using a binary encoding is that we can use quantum circuits for arithmetic operations. As we will discuss more in depth in 3.3.1.1 any Boolean circuit can be made reversible, and any reversible circuit can be implemented using single-qubit NOT gates and three-qubit Toffoli gates. Since most of the classical Boolean circuits for arithmetic operations operate with a number of gates of \(O(\text{poly}(c_1,c_2))\), this implies a number of quantum gates of \(O(\text{poly}(c_1,c_2))\) for the corresponding quantum circuit. Extending the analogy with classical computation allows us to introduce the arithmetic model of computation for performing operations on binary encoded numbers in constant time.
Definition 3.2 (Quantum arithmetic model (João F. Doriguello et al. 2022)) Given \(c_1, c_2 \in \mathbb{N}\) specifying fixed-point precision numbers as in Definition 3.1, we say we use a quantum arithmetic model of computation if the four arithmetic operations can be performed in constant time in a quantum computer.
Beware that using Definition 3.1 is not the only possibile choice. For example, most of the non-modular and modular arithemtic circuits are expressed in 2s complement. For a comprehensive and optimized list of results about this topic, the interest reader can read (Luongo et al. 2024). As for the classical counterpart, a quantum algorithm’s complexity does not take into account the cost of performing arithmetic operations, as the number of digits of precisions used to represents numbers is a constant, and does not depend on the input size. However, when estimating the resources needed to run an algorithm on a quantum computer, specifying these values becomes important. For a good example of a complete resource analysis, including arithmetic operations in fixed-point precision, of common algorithms in quantum computational finance we refer to (Chakrabarti et al. 2021).
3.1.2 Amplitude encoding
Amplitude encoding is a way to represent a vector \(x\) of size \(n\) (where \(n\) is a power of \(2\)) in the amplitudes of an \(\log(n)\) qubit pure state. We can map a vector \(x \in \mathbb{R}^{N}\) (or even \(\in \mathbb{C}^{N}\)) to the following quantum state:
\[\begin{equation} |x\rangle = \frac{1}{{\left \lVert x \right \rVert}}\sum_{i=0}^{N-1}x_i|i\rangle = \|x\|^{-1}x, \tag{3.2} \end{equation}\]
Sometimes, amplitude encoding is also known as quantum sampling access, as sampling from a quantum state we prepare can also be interpreted as sampling from a probability distribution. In fact, if the amplitude of a computational basis \(|i\rangle\) is \(\alpha_i\), then we sample \(|i\rangle\) with probability \(|\alpha_i|^2\). Observe from the state in the above equation we are actually representing an \(\ell_2\)-normalized version of the vector \(x\). Therefore we have “lost” the information on the norm of the vector \(x\). However we will see how this is not a problem when we work with more than one vector. This type of encoding can be generalized to matrices. Let \(x(i)\) be the \(i\)-th row of \(X \in \mathbb{R}^{n \times d}\), a matrix with \(n\) rows and \(d\) columns (here we take again \(n\) and \(d\) to be a power of \(2\)). Then we can encode \(X\) with \(\lceil log(d) \rceil +\lceil log(n) \rceil\) qubits as:
\[\begin{equation} |X\rangle = \frac{1}{\sqrt{\sum_{i=1}^n {\left \lVert x(i) \right \rVert}^2 }} \sum_{i=1}^n {\left \lVert x(i) \right \rVert}|i\rangle|x(i)\rangle \tag{3.3} \end{equation}\]
Exercise 3.1 Check that Equation (3.3) is equivalent to \[\begin{equation} |X\rangle = \frac{1}{\sqrt{\sum_{i,j=1}^{n,d} |X_{ij}|^2}} \sum_{i,j=1}^{n,d} X_{ij}|i\rangle|j\rangle, \tag{3.4} \end{equation}\]
From an algorithms perspective, amplitude encoding is useful because it requires a logarithmic number of qubits with respect to the vector size, which might seem to lead to an exponential saving in physical resources when compared to classical encoding techniques. A major drawback of amplitude encoding is that, in the worst case, for the majority of states, it requires a circuit of size \(\Omega(N)\).
3.1.3 Block encoding
Block encoding is another type of encoding for working with matrices on a quantum computer. More precisely, we want to encode a matrix into a unitary that has a circuit representation on a quantum computer. As it will become clear in the next chapters, being able to perform such encoding unlocks many possibilities in terms of new quantum algorithms.
Definition 3.3 (Block encoding of a matrix) Let \(A \in \mathbb{R}^{N \times N}\) be a square matrix for \(N = 2^n\) for \(n\in\mathbb{N}\), and let \(\alpha \geq 1\). For \(\epsilon > 0\), we say that a \((n+a)\)-qubit unitary \(U_A\) is a \((\alpha, a, \epsilon)\)-block encoding of \(A\) if
\[\begin{equation} \| A - \alpha ( \langle 0|^{\otimes a} \otimes I) U_A (|0\rangle^{\otimes a} \otimes I) \|_2 \leq \epsilon \end{equation}\]
It is useful to observe that an \((\alpha, a, \epsilon)\)-block encoding of \(A\) is just a \((1, a, \epsilon)\)-block encoding of \(A/\alpha\). Often, we do not want to take into account the number of qubits \(a\) we need to create the block encoding because these are expected to be negligible. Therefore, some definitions of block encoding in the literature use the notation \((\alpha, \epsilon)\) or the notation \(\alpha\)-block encoding if the error is \(0\). Note that the matrix \(U_A \in \mathbb{R}^{(N+\kappa) \times (N+\kappa)}\) has the matrix \(A\) encoded in the top-left part:
\[\begin{equation} U_A = \begin{pmatrix} A & . \\ . & . \end{pmatrix}. \tag{3.5} \end{equation}\]
3.1.4 Angle encoding
Another way to encode vectors, as defined by (M. Schuld and Petruccione 2021), is with angle encoding. This technique encodes information as angles of the Pauli rotations \(\sigma_x(\theta)\), \(\sigma_y(\theta)\), \(\sigma_z(\theta)\). Given a vector \(x \in \mathbb{R}^n\), with all elements in the interval \([0,2\pi]\); the technique seeks to apply \(\sigma_{\alpha}^i(x_i)\), where \(\alpha \in \{x,y,z \}\) and \(i\) refers to the target qubit. The resulting state is said to be an angle encoding of \(x\) and has a form given by
\[\begin{equation} |x\rangle = \prod_{i=1}^{n} \sigma_{\alpha}^{i}(x_i)|0\rangle^{\otimes n} \tag{3.6} \end{equation}\]
This technique’s advantages lies in its efficient resource utilization, which scales linearly for number of qubits. One major drawback is that it is difficult to perform arithmetic operations on the resulting state, making it difficult to apply to quantum algorithms.
3.1.5 Graph encoding
A graph is as a tuple \(G =(V,E)\), where \(V\) are the vertices in the graph and \(E\) are the edges, where \(E \subseteq V \times V\). For graph encoding we require unidirected graphs in which if \(( v_i, v_j ) \in E\) then \(( v_j, v_i ) \in E\). Unidirected graphs can be either simple or multigraphs. A simple unidirected graph is one without self loops and at most a single edge connecting two vertices, whilst a unidirected multigraph can have self loops or multiple edges between two vertices. Graph encoding is possible for unidirected multigraphs with self loops but at most a single edge between two vertices.
A graph \(G\) will be represented as an \(N=|V|\) qubit pure quantum state \(|G\rangle\) such that
\[\begin{equation} K_G^v|G\rangle = |G\rangle, \;\; \forall v \in V \tag{3.7} \end{equation}\]
where \(K_G^v = \sigma_x^v\prod_{u \in N(v)}\sigma_z^u\), and \(\sigma_x^u\) and \(\sigma_z^u\) are the Pauli operators \(\sigma_x\) and \(\sigma_z\) applied to the \(u^{th}\) qubit.
Given a graph \(G\) with \(V\) vertices and edges \(E\), take \(N=|V|\) qubits in the \(|0\rangle^{\otimes N}\) state, apply \(H^{\otimes N}\), producing the \(|+\rangle^{\otimes N}\) state where \(|+\rangle = \frac{|0\rangle + |1\rangle}{\sqrt{2}}\). Then apply a controlled \(Z\) rotation between qubits connected by an edge in \(E\). It is worth noting that 2 different graphs can produce the same graph state \(|G\rangle\). In particular if a graph state \(|\tilde{G}\rangle\) can be obtained from a graph state \(|G\rangle\) by only applying local Clifford group operators, the 2 graphs are said to be LC-equivalent. The work by (L. Zhao, Pérez-Delgado, and Fitzsimons 2016) has interesting application of this type of encoding.
3.1.6 One-hot encoding
Another possible way of encoding vectors as quantum states introduced by (Mathur et al. 2022) is one-hot amplitude encoding, also known as unary amplitude encoding, which encodes a normalized vector \(x \in \mathbb{C}^n\) onto \(n\) qubits. The vector values \(x_i \in \mathbb{C}\) will be stored in the amplitudes of the states that form the \(2^n\)-dimensional canonical basis, i.e, the states with only one \(1\) and the rest \(0\)s. This corresponds to preparing the state:
\[\begin{equation} |x\rangle = \frac{1}{||x||} \sum_{i=1}^n x_i |e_i\rangle, \tag{3.8} \end{equation}\]
where, for some integer \(i\), the states \(e_i\) take the form \(e_i = 0^{i-1}10^{n-i}\).
3.2 Quantum memory
Having seen possible ways to represent data on a quantum computer, we will now take the first step toward understanding how to create quantum states that are representing numbers using these encodings. The first step involves understanding quantum memory, which plays a key role in various quantum algorithms/problems such as: Grover’s search, solving the dihedral hidden subgroup problem, collision finding, phase estimation for quantum chemistry, pattern recognition, machine learning algorithms, cryptanalysis, and state preparation.
To work with quantum memory we need to define a quantum memory model of computation, which enables us to accurately calculate the complexity of quantum algorithms. In this framework we divide a quantum computation into a data pre-processing step and a computational step. Quantum memory allows us to assume that the pre-processed data can be easily accessed (as in classical computers). In this model, since the pre-processing is negligible, and has to be performed only once, the complexity of a quantum algorithm is fully characterized by the computational step. This understanding formalizes a quantum computation in two distinct components: a quantum processing unit and a quantum memory device. Two notable examples of quantum memory devices are the quantum random access memory (\(\mathsf{QRAM}\)) and the quantum random access gates (\(\mathsf{QRAG}\)). It is important to note that having access to a quantum memory device is associated with fault tolerant quantum computers.
This section will first introduce the quantum memory model of computation (3.2.1). This will be followed by the formalization of a quantum computation in the memory model via a quantum processing unit (\(\mathsf{QPU}\)) and a quantum memory device (\(\mathsf{QMD}\)) (3.2.2), where the \(\mathsf{QRAM}\) and \(\mathsf{QRAG}\) will be presented as possible implementation of the \(\mathsf{QMD}\).
3.2.1 The quantum model of computation with and without memory
As discussed in the Section 2.3 of the previous chapter, in quantum computing we often work in a oracle model, also called black-box model of quantum computation. This section is devoted to the formalization of this model of computation. The word “oracle”, (a word referencing concepts in complexity theory), is used to imply that an application of the oracle has \(\mathcal{O}(1)\) cost, i.e. we do not care about the cost of implementing the oracle in our algorithm. A synonym of quantum oracle model is quantum query model, which stresses the fact that we can only use the oracle to perform queries.
To appreciate the potential of quantum algorithms, it is important to understand the quantum memory model. This is because we want to compare quantum algorithms with classical algorithms. Understanding the quantum memory model makes sure that we not favor any of the approaches, ensuring a fair evaluation of their performance across different computational models and memory architectures. Understanding classical memory is also important for classical algorithms. Memory limitations make the analysis of big datasets challenging. This limitation is exacerbated when the random-access memory is smaller than the dataset to analyze, as the bottleneck of computational time switch from being the number of operations to the time to move data from the disk to the memory. Hence, algorithms with super linear runtime (such as those based on linear algebra) become impractical for large input size.
As we will formalize later, the runtime for analyzing a dataset represented by a matrix \(A \in \mathbb{R}^{n \times d}\) using a quantum computer is given by the time to preprocess the data (i.e., creating quantum accessible data structures) and the runtime of the quantum algorithm. Importantly, the pre-processing step needs to be done only once, allowing one to run (different) quantum algorithms on the same matrix. We can see this pre-processing step as a way of encoding and/or storing the data: once the matrix is pre-processed, we can always retrieve the matrix in the original representation (i.e. it is a loss less encoding). This step bears some similarities with the process of loading the data from the disk in RAM Therefore, because the pre-processing step is analyzed differently from the runtime, when we work with a quantum algorithm that has quantum access to some classical data, we have the following model in mind.
Definition 3.4 (Costing in the quantum memory model) An algorithm in the quantum memory model that processes a data-set of size \(m\) has two steps:
- A pre-processing step with complexity \(\widetilde{O}(m)\) that constructs an efficient quantum access to the data
- A computational step where the algorithm has quantum access to the data structures constructed in step 1.
The complexity of the algorithm in this model is measured by the cost for step 2.
Let’s consider an example. We will see that many of the quantum algorithms considered in this book have a computational complexity expressed (in number of operations of a certain kind) as some functions of the matrix and the problem. Consider a classical algorithm with a runtime of \(\widetilde{O} \left( \frac{\left\lVert A\right\rVert_0\kappa(A)}{\epsilon^2}\log(1/\delta) \right)\) calls to the classical memory (and coincidentally, CPU operations). Here \(\epsilon\) is some approximation error in the quantity we are considering, \(\kappa(A)\) is the condition number of the matrix, \(\delta\) the failure probability. The quantum counterpart of this algorithm has a runtime of \(O(\left\lVert A\right\rVert_0)\) classical operation for pre-processing and
\[\begin{equation} \widetilde{O}(\text{poly}(f(A)), \text{poly}(\kappa(A)), \text{poly}(1/\epsilon), \text{poly}(\log(nd)), \text{poly}(\log(1/\delta)) ) \tag{3.9} \end{equation}\]
queries to the quantum memory (and coincidentally, number of operations). Here, \(f(A)\) represents some size-independent function of the matrix that depends on the properties of \(A\) which can be chosen to be \(\|A\|_F\): the Frobenius norm of the matrix. Importantly, note that in the runtime of the quantum algorithm there is no dependence on \(\|A\|_0\).
The first step, i.e., loading data (for example a matrix \(A\)) onto a quantum memory gives an additive price of \(\widetilde{O}(\left\lVert A\right\rVert_0)\), and is computationally easy to implement. In some cases this can be done on the fly, with only a single pass over the dataset, for example while receiving each of the rows of the matrix. For more complex choices of \(f(A)\), the construction of the data structure needs only a few (constant) numbers of passes over the dataset. As pre-processing the data is negligible, we expect quantum data analysis to be faster than classical data analysis. However, there is no need to employ quantum data analysis for small datasets if classical data analysis is sufficient.
In the quantum memory model, we assumed that the pre-processing step to be negligible in cost, and thereby claim that there is significant practical speedup when using quantum algorithms compared to classical algorithms. However, a proper comparison for practical applications needs to include the computational cost of the loading process, which may or may not remove the exponential gap between the classical and the quantum runtime. Nevertheless, even when the pre-processing step is included, we expect the overall computational cost to largely favor the quantum procedure. This analysis can be done only with a proper understanding of the quantum memory model.
Having a clear and deep understanding of the quantum memory model can help us understand the power and limitations of classical computers as well. The past few years saw a trend of works proposing “dequantizations” of quantum machine learning algorithms. These algorithms explored and sharpened some ideas (Tang 2018) to leverage a classical data structure to perform importance sampling on input data to have classical algorithm with polylogarithmic runtimes in the size of the input. This data structure is very similar to the one used in many quantum machine learning algorithms (see Section 3.3.2.2). As a result, many quantum algorithms which had an exponential separation with their classical counterpart now have at most a polynomial speedup compared to the classical algorithm. However, these classical algorithms have a worse dependence in other parameters (like condition number, Frobenius norm, rank, and so on) that will make them disadvantageous in practice (i.e., they are slower than the fastest classical randomized algorithms (Arrazola et al. 2020)). With that said, having small polynomial speedup is not something to be critical about: even constant speedups matter a lot in practice! Overall, dequantizations and polynomial speedups highlight the importance of clearly understanding the techniques behind loading classical data in quantum computers.
3.2.2 The quantum processing unit and quantum memory device
In this section, we formally define a model of a quantum computer with quantum access to memory. We can intuitively understand this model by separating the available Hilbert space in two: a part dedicated to computing, the Quantum Processing Unit (\(\mathsf{QPU}\)) and a part dedicated to storing, the Quantum Memory Device (\(\mathsf{QMD}\)).
The qubits which comprise the \(\mathsf{QPU}\) are assigned to either an input register or a workspace register; whilst the qubits which comprise the \(\mathsf{QMD}\) are assigned to either a ancillary register or a memory register. Two other registers, the address register and the target register, are shared by the \(\mathsf{QPU}\) and \(\mathsf{QMD}\) and allow for communication between the two Hilbert spaces. A depiction of the architecture of a \(\mathsf{QPU}\) with access to a \(\mathsf{QMD}\) can be seen in Figure 3.1. Before defining a model of a quantum computer with quantum access to memory, we will first formally define a computation with only the quantum processing unit \(\mathsf{QPU}\).
Definition 3.5 (Quantum Processing Unit (Allcock et al. 2023)) A Quantum Processing Unit(\(\mathsf{QPU}\)) of size \(m\) is defined as a tuple \((\mathtt{I}, \mathtt{W},\mathcal{G})\) consisting of
- an \(m_{\mathtt{I}}\)-qubit Hilbert space called \(\mathtt{I}\);
- an \((m-m_{\mathtt{I}})\)-qubit Hilbert space called \(\mathtt{W}\);
- a constant-size universal gate set \(\mathcal{G}\subset\mathcal{U}(\mathbb{C}^{4\times 4})\).
The qubits in the workspace \(\mathtt{W}\) are called ancillary qubits or simply ancillae. An input to the \(\mathsf{QPU}\), or quantum circuit, is a tuple \((T,|\psi_{\mathtt{I}}\rangle,C_1,\dots,C_T)\) where \(T\in\mathbb{N}\), \(|\psi_{\mathtt{I}}\rangle\in\mathtt{I}\), and, for each \(t\in\{1,\dots,T\}\), \(C_t\in\mathcal{I}(\mathcal{G})\) is a set of instructions from a set \(\mathcal{I}(\mathcal{G})\) of possible instructions. Starting from the state \(|\psi_0\rangle := |\psi_\mathtt{I}\rangle|0\rangle_{\mathtt{W}}^{\otimes (m-m_\mathtt{I})}\), at each time step \(t\in\{1,\dots, T\}\) we obtain the state \(|\psi_t\rangle = C_t|\psi_{t-1}\rangle\in\mathtt{I}\otimes\mathtt{W}\). The instruction set \(\mathcal{I}(\mathcal{G})\subset\mathcal{U}(\mathbb{C}^{2^m\times 2^m})\) consists of all \(m\)-qubit unitaries on \(\mathtt{I}\otimes\mathtt{W}\) of the form
\[\begin{equation} \prod_{i=1}^k (\mathsf{U}_i)_{\to I_i} \end{equation}\]
for some \(k\in\mathbb{N}\), \(\mathsf{U}_1,\dots,\mathsf{U}_k\in\mathcal{G}\) and pair-wise disjoint non-repeating sequences \(I_1,\dots,I_k\in[m]^{\leq 2}\) of at most \(2\) elements. We say that \(\sum_{i=1}^k |I_i|\) is the of the corresponding instruction. We say that \(T\) is the of the input to the \(\mathsf{QPU}\), while its is the sum of the sizes of the instructions \(C_1,\dots,C_T\).
Note that in this definition the circuit size differs from the standard notion of circuit size, which is the number of selected gates from \(\mathcal{G}\), up to a factor of at most \(2\).
Exercise 3.2 Can you explain why the circuit size differs from the standard notion of circuit size by up to a factor of at most \(2\)
Moreover, in this framework, the locations of the address and target registers are fixed. One could imagine a more general setting where the address and target registers are freely chosen from the workspace. This case can be handled by this model with minimal overhead, e.g. by performing \(\ell\)-\(\mathsf{SWAP}\) gates to move the desired workspace qubits into the address or target register locations.
Adding access to a \(\mathsf{QMD}\) changes how we define the model of computation. In practice, a call to the \(\mathsf{QMD}\) sees the address register selecting a unitary from a set of unitaries \(\mathcal{V}\) and applying it to both the target and memory register. It is important to stress that even though a call to the \(\mathsf{QMD}\) might require gates from a universal gate set, the underlying quantum circuit implementing such a call is , i.e., does not change throughout the execution of a quantum algorithm by the \(\mathsf{QPU}\), or even between different quantum algorithms. Below we find the full definition of a quantum computation of a \(\mathsf{QPU}\) with access to a \(\mathsf{QMD}\).
Definition 3.6 (Quantum Processing Unit and Quantum Memory Device (Allcock et al. 2023)) We consider a model of computation comprising a Quantum Processing Unit(\(\mathsf{QPU}\)) of size \(\text{poly}\log(n)\) and a Quantum Memory Device (\(\mathsf{QMD}\)) of \(n\) memory registers, where each register is of \(\ell\)-qubit size (for \(n\) a power of \(2\)). A \(\mathsf{QPU}\) and a \(\mathsf{QMD}\) are collectively defined by a tuple \((\mathtt{I}, \mathtt{W}, \mathtt{A}, \mathtt{T}, \mathtt{Aux}, \mathtt{M}, \mathcal{G}, \mathsf{V})\) consisting of
- two \((\operatorname{poly}\log{n})\)-qubit Hilbert spaces called \(\mathtt{I}\) and \(\mathtt{W}\) owned solely by the \(\mathsf{QPU}\);
- a \((\log{n})\)-qubit Hilbert space called \(\mathtt{A}\) shared by both \(\mathsf{QPU}\) and \(\mathsf{QMD}\);
- an \(\ell\)-qubit Hilbert space called \(\mathtt{T}\) shared by both \(\mathsf{QPU}\) and \(\mathsf{QMD}\);
- a \((\text{poly}{n})\)-qubit Hilbert space called \(\mathtt{Aux}\) owned solely by the \(\mathsf{QMD}\);
- an \(n\ell\)-qubit Hilbert space called \(\mathtt{M}\) comprising \(n\) registers \(\mathtt{M}_0, \ldots, \mathtt{M}_{n-1}\), each containing \(\ell\) qubits, owned solely by the \(\mathsf{QMD}\);
- a constant-size universal gate set \(\mathcal{G}\subset\mathcal{U}(\mathbb{C}^{4\times 4})\);
- a function \(\mathsf{V} : [n] \to \mathcal{V}\), where \(\mathcal{V}\subset \mathcal{U}(\mathbb{C}^{2^{2\ell}\times 2^{2\ell}})\) is a \(O(1)\)-size subset of \(2\ell\)-qubit gates.
The qubits in \(\mathtt{W}\), \(\mathtt{A}\), \(\mathtt{T}\), and \(\mathtt{Aux}\) are called ancillary qubits or simply ancillae. An input to the \(\mathsf{QPU}\) with a \(\mathsf{QMD}\), or quantum circuit, is a tuple \((T,|\psi_\mathtt{I}\rangle,|\psi_{\mathtt{M}}\rangle,C_1,\dots,C_T)\) where \(T\in\mathbb{N}\), \(|\psi_{\mathtt{I}}\rangle\in\mathtt{I}\), \(|\psi_{\mathtt{M}}\rangle\in\mathtt{M}\), and, for each \(t\in\{1,\dots,T\}\), \(C_t\in\mathcal{I}(\mathcal{G},\mathsf{V})\) is an instruction from a set \(\mathcal{I}(\mathcal{G},\mathsf{V})\) of possible instructions. The instruction set \(\mathcal{I}(\mathcal{G},\mathsf{V})\) is the set \(\mathcal{I}(\mathcal{G})\) acting on \(\mathtt{I}\otimes\mathtt{W}\otimes\mathtt{A}\otimes\mathtt{T}\) augmented with the call-to-the-\(\mathsf{QMD}\) instruction that implements the unitary
\[\begin{equation} |i\rangle_{\mathtt{A}}|b\rangle_{\mathtt{T}}|x_i\rangle_{\mathtt{M}_i}|0\rangle^{\otimes \text{poly}{n}}_{\mathtt{Aux}} \mapsto|i\rangle_{\mathtt{A}}\big(\mathsf{V}(i)|b\rangle_{\mathtt{T}}|x_i\rangle_{\mathtt{M}_i}\big)|0\rangle^{\otimes \text{poly}{n}}_{\mathtt{Aux}}, \qquad \forall i\in[n],b,x_i\in\{0,1\}^\ell. \end{equation}\]
Starting from \(|\psi_0\rangle|0\rangle^{\otimes \text{poly}{n}}_{\mathtt{Aux}}\), where \(|\psi_0\rangle := |\psi_\mathtt{I}\rangle|0\rangle^{\otimes\text{poly}\log{n}}_{\mathtt{W}}|0\rangle_{\mathtt{A}}^{\otimes \log{n}}|0\rangle_{\mathtt{T}}^{\otimes \ell}|\psi_\mathtt{M}\rangle\), at each time step \(t\in\{1,\dots, T\}\) we obtain the state \(|\psi_t\rangle|0\rangle^{\otimes \text{poly}{n}}_{\mathtt{Aux}} = C_t(|\psi_{t-1}\rangle|0\rangle^{\otimes \text{poly}{n}}_{\mathtt{Aux}})\), where \(|\psi_t\rangle\in \mathtt{I}\otimes \mathtt{W}\otimes \mathtt{A}\otimes \mathtt{T}\otimes \mathtt{M}\).
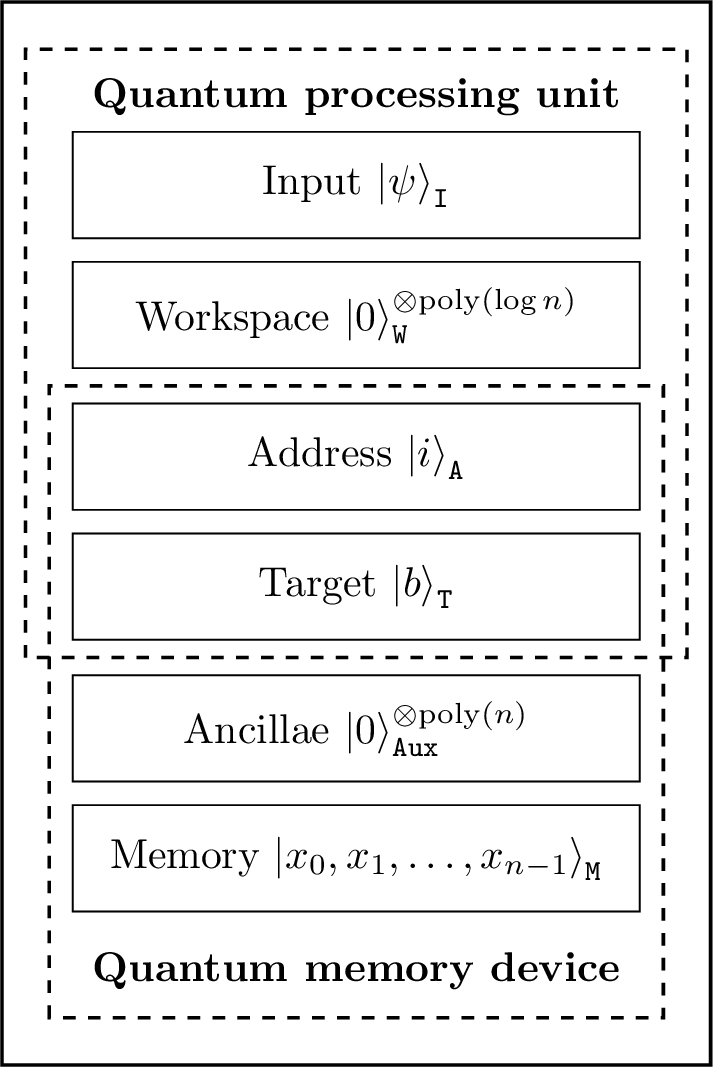
Figure 3.1: The architecture of a Quantum Processing Unit(\(\mathsf{QPU}\)) with access to a quantum memory device(\(\mathsf{QMD}\)). The \(\mathsf{QPU}\) is composed of a \(\text{poly}\log(n)\)-qubit input register \(\mathtt{I}\) and workspace \(\mathtt{W}\). The \(\mathsf{QMD}\) is composed of an \(nl\)-qubit memory array \(\mathtt{M}\), composed of \(n\) memory cells each of size \(l\)-qubits, and a \(\text{poly}(n)\)-qubit auxiliary register \(\mathtt{Aux}\). Two registers, the \(\log(n)\)-qubit address register \(\mathtt{A}\) and an \(l\)-qubit target register \(\mathtt{T}\), are shared between the \(\mathsf{QPU}\) and the \(\mathsf{QMD}\).
This model can be seen as a refined version of the one described in (Buhrman et al. 2022), where the authors divide the qubits of a quantum computer into work and memory qubits. Given \(M\) memory qubits, their workspace consists of \(O(\log M)\) qubits, of which the address and target qubits are always the first \(\lceil\log M\rceil + 1\) qubits. However, address and target qubits are not considered to be shared by the \(\mathsf{QMD}\), and there is no mention of ancillary qubits mediating a call to the \(\mathsf{QMD}\). The inner structure of the \(\mathsf{QMD}\) is abstracted away by assuming access to the unitary of a \(\mathsf{QRAG}\) (see Definition 3.10 later). This model, in contrast, “opens” the quantum memory device, and allows for general fixed unitaries, including \(\mathsf{QRAM}\) and \(\mathsf{QRAG}\).
In addition, this model does not include measurements. These can easily be performed on the output state \(|\psi_T\rangle\) if need be. Furthermore the position of the qubits is not fixed within the architecture, allowing for long-range interactions through, for example, multi-qubit entangling gates. This feature is not always possible in physical the real world since some quantum devices, such as superconducting quantum computers, don’t allow for long-range interactions between qubits. For a model of computation which take in consideration physically realistic device interactions we suggest the work by (Beals et al. 2013).
We stress the idea that call to the \(\mathsf{QMD}\) is defined by the function \(\mathsf{V}\) and quantum memory device is defined by the unitary that it implements. In many applications, one is interested in some form of reading a specific entry from the memory, which corresponds to the special cases where the \(\mathsf{V}(i)\) unitaries are made of controlled single-qubit gates, and to which the traditional \(\mathsf{QRAM}\) belongs.
3.2.2.1 The LAQCC model of quantum computation
We can also consider an alternative model of quantum computation to the one in Definition ??: the LAQCC model, which stands for Local Alternating Quantum Classical Computations. LAQCC is a hybrid quantum-classical computational framework (Buhrman et al. 2023b). This model assumes quantum hardware with specific topology and connectivity, enabling the measurement of certain (but not necessarily all) qubits. The measurement results are then used to perform intermediate classical computations, which, in turn, control subsequent quantum circuits. This process can alternate between quantum and classical layers multiple times, allowing for iterative computation. The authors did not consider an explicit formulation of the quantum memory device. However, it is possible to perform amplitude encoding of a certain class of states in constant depth. Formally, it is defined as follows.
Definition 3.7 (Local Alternating Quantum Classical Computations (Buhrman et al. 2023b)) Let \(\text{LAQCC}(\mathcal{Q}, \mathcal{C}, d)\) be the class of circuits such that:
- Every quantum layer implements a quantum circuit \(Q \in \mathcal{Q}\) constrained to a grid topology;
- Every classical layer implements a classical circuit \(C \in \mathcal{C}\);
- There are \(d\) alternating layers of quantum and classical circuits;
- After every quantum circuit \(Q\), a subset of the qubits is measured;
- The classical circuit receives input from the measurement outcomes of previous quantum layers;
- The classical circuit can control quantum operations in future layers.
The allowed gates in the quantum and classical layers are given by \(\mathcal{Q}\) and \(\mathcal{C}\), respectively. Furthermore, we require a circuit in \(\text{LAQCC}(\mathcal{Q}, \mathcal{C}, d)\) to deterministically prepare a pure state on the all-zeroes initial state.
3.2.2.2 The QRAM
A type of \(\mathsf{QMD}\) of particular interest is the \(\mathsf{QRAM}\), which is the quantum equivalent of a classical Random Access Memory (RAM), that stores classical or quantum data and allows for superposition-based queries. More specifically, a \(\mathsf{QRAM}\) is a device comprising a memory register that stores data, an address register that points to the memory cells to be addressed, and a target register into which the content of the addressed memory cells is copied. If necessary, it also includes an auxiliary register supporting the overall operation, which is reset to its initial state at the end of the computation. Formally, we define it as:
Definition 3.8 (Quantum Random Access Memory) Let \(n\in\mathbb{N}\) be a power of \(2\) and \(f(i) = \mathsf{X}\) for all \(i\in[n]\). A \(\mathsf{QRAM}\) of memory size \(n\) is a \(\mathsf{QMD}\) with \(\mathsf{V}(i) = \mathsf{C}_{\mathtt{M}_i}\)-\(\mathsf{X}_{\to\mathtt{T}}\). Equivalently, it is a \(\mathsf{QMD}\) that maps
\[\begin{equation} |i\rangle_{\mathtt{A}}|b\rangle_{\mathtt{T}}|x_0,\dots,x_{n-1}\rangle_{\mathtt{M}} \mapsto |i\rangle_{\mathtt{A}}(f(i)^{x_i}|b\rangle_{\mathtt{T}}) |x_0,\dots,x_{n-1}\rangle_{\mathtt{M}} \quad\quad \forall i\in[n], b,x_0,\dots,x_{n-1}\in\{0,1\}. \end{equation}\]
A unitary performing a similar mapping often goes under the name of quantum read-only memory (\(\mathsf{QROM}\)) The difference with \(\mathsf{QRAM}\) is that that this term stresses that they don’t allow data to be added or modified. Oftentimes, the authors using this term are considering a circuit, as described in section ??.
Instead assuming to have access to a \(\mathsf{QRAM}\) requires a protocol for the pre-processing of the data and creation of a data structure in time which is asymptotically linear in the data size (as indicated by definition ??).
Equipped with definition 3.8) we can formalize what it means to have quantum query access, which is also referred to as \(\mathsf{QRAM}\) access or as having “\(x\) is in the \(\mathsf{QRAM}\)”. We will formalize the case of having a vector \(x \in (\{0,1\}^m)^N\) stored in the \(\mathsf{QRAM}\).
Definition 3.9 (Quantum query access to a vector stored in the QRAM) Given \(x \in (\{0,1\}^m)^N\), we say that we have quantum query access to \(x\) stored in the \(\mathsf{QRAM}\) if we have access to a unitary operator \(U_x\) such that \(U_x|i\rangle|b\rangle = |i\rangle|b \oplus x_i\rangle\) for any bit string \(b\in\{0,1\}^m\).
In practical terms when analyzing the complexity of a quantum algorithm with a \(\mathsf{QRAM}\) we need to take in consideration three factors: the circuit size of the quantum algorithm as introduced in definition ??, the number of queries to the \(\mathsf{QRAM}\) and the complexity each \(\mathsf{QRAM}\) query. We emphasize that the complexity that arises due to a query to the \(\mathsf{QRAM}\) is still an open question. Details of some possible implementations will be discussed in section 3.3.
| Method | Size | Ancilla | Depth | Comment | |
|---|---|---|---|---|---|
| 1 | Multiplexer | O(nm) | O(nm) | ||
| 2 | Bucket Brigade | ||||
| 3 | FanOut BB | Uses FanOut gates | |||
| 4 | Trading | \(O(n)\) | \(2n + 2\) | \(O(n)\) | |
| 5 | One-hot encoding FanOut | \(6n\log{n} + O(n\log\log{n})\) \(\:^+\) | \(2n\log{n}\log\log{n} + O(n\log{n})\) | \(O(1)\) | |
| 6 | One-hot encoding GT-gate | \(6n\log{n} + O(n\log\log{n})\) \(\:^+\) | \(2n\log{n}\log\log{n} + O(n\log{n})\) | \(O(1)\) | |
| 7 | Fourier | ||||
| 8 | Circuit | \(O(N2^m)\) | \(\lambda\) | \(\lambda > Nm\) |
3.2.2.3 The QRAG
Another type of quantum memory device is the quantum random access gate(\(\mathsf{QRAG}\)). This quantum memory device was introduced in the paper of (Andris Ambainis 2007) and performs a \(\mathsf{SWAP}\) gate between the target register and some portion of the memory register specified by the address register. The \(\mathsf{QRAG}\) finds applications in quantum algorithms for element distinctness, collision finding and random walks on graphs. The formal definition is:
Definition 3.10 (Quantum Random Access Gate) Let \(n\in\mathbb{N}\) be a power of \(2\). A \(\mathsf{QRAG}\) of memory size \(n\) is a \(\mathsf{QMD}\) with \(\mathsf{V}(i) = \mathsf{SWAP}_{\mathtt{M}_i\leftrightarrow \mathtt{T}}\), \(\forall i\in[n]\). Equivalently, it is a \(\mathsf{QMD}\) that maps
\[\begin{equation} |i\rangle_{\mathtt{A}}|b\rangle_{\mathtt{T}}|x_0,\dots,x_{n-1}\rangle_{\mathtt{M}} \mapsto |i\rangle_{\mathtt{A}}|x_i\rangle_{\mathtt{T}} |x_0,\dots,x_{i-1},b,x_{i+1},\dots,x_{n-1}\rangle_{\mathtt{M}} \quad \forall i\in[n], b,x_0,\dots,x_{n-1}\in\{0,1\}. \end{equation}\]
It turns out that the \(\mathsf{QRAG}\) can be simulated with a \(\mathsf{QRAM}\), but the \(\mathsf{QRAM}\) can be simulated with the \(\mathsf{QRAG}\) by requiring single qubit operations (which are not present in the model of computation of definition 3.6). We will present the proof for the simulation of the \(\mathsf{QRAM}\) with a \(\mathsf{QRAG}\) and leave the opposite proof as exercise.
Theorem 3.1 (Simulating QRAM with QRAG.) A query to a \(\mathsf{QRAM}\) of memory size \(n\) can be simualted using 2 queries to a \(\mathsf{QRAG}\) of memory size \(n\), 3 two-qubit gates, and \(1\) workspace qubit.
Proof. Start with the input \(|i\rangle_{\mathtt{A}}|0\rangle_{\mathtt{Tmp}}|b\rangle_{\mathtt{T}}|x_0,\dots,x_{n-1}\rangle_{\mathtt{M}}\) by using an ancillary qubit \(\mathtt{Tmp}\) for the workspace. Use the \(\mathtt{SWAP}_{\mathtt{T} \leftrightarrow \mathtt{Tmp}}\) gate to obtain \(|i\rangle_{\mathtt{A}}|b\rangle_{\mathtt{Tmp}}|0\rangle_{\mathtt{T}}|x_0,\dots,x_{n-1}\rangle_{\mathtt{M}}\). A query to the \(\mathsf{QRAG}\) then leads to \(|i\rangle_{\mathtt{A}}|b\rangle_{\mathtt{Tmp}}|x_i\rangle_{\mathtt{T}}|x_0,\dots,x_{n-1}\rangle_{\mathtt{M}}\). Use a \(\mathtt{C}_{\mathtt{T}}\)-\(\mathtt{X}_{\rightarrow \mathtt{Tmp}}\) from register \(\mathtt{T}\) to register \(\mathtt{Tmp}\), and query again the \(\mathsf{QRAG}\), followed by a \(\mathtt{SWAP}_{\mathtt{T} \leftrightarrow \mathtt{Tmp}}\) gate, to obtain the desired state \(|i\rangle_{\mathtt{A}}|b \oplus x_i\rangle_{\mathtt{T}}|x_0,\dots,x_{n-1}\rangle_{\mathtt{M}}\) after discarding the ancillary qubit.
Exercise 3.3 Assuming that single-qubit gates can be freely applied onto the memory register \(\mathtt{M}\) of any \(\mathsf{QRAM}\), then show that a \(\mathsf{QRAG}\) of memory size \(n\) can be simulated using \(3\) queries to a \(\mathsf{QRAM}\) of memory size \(n\) and \(2(n+1)\) Hadamard gates.
TODO make teheorem of the collowing comment.
3.2.2.4 Memory compression in sparse QRAG models
Assuming that the data is sparse is a common assumption when developing quantum algorithms since it significantly simplifies computations. Applying it to compress quantum algorithms with access to a \(\mathsf{QRAG}\) was first proposed by (Andris Ambainis 2007), elaborated further in (Jeffery 2014), (Bernstein et al. 2013), and finally formalized in (Buhrman et al. 2022).
Informally, a quantum algorithm is considered sparse if the number of queries to a \(\mathsf{QRAG}\) of size \(M\) are made with a small number of quantum states. More formally, we start by recalling that in a quantum computational model of definition 3.6 we split the qubits in several registers including a \(M\) qubit memory register and a \(W\) qubit working register. If throughout the computation the queries to the \(\mathsf{QRAG}\) are made using only a constant set of quantum states which have a maximum Hamming weight(which is the number of \(1\)’s in the bit string) of \(m \lll M\), then the algorithm is said to be \(m\)-sparse. The trick to making this definition work is realizing that the \(\mathtt{SWAP}\) gate can be used to exchange states between the working register and the states with low hamming weight of the target register.
Confusingly, the authors of (Buhrman et al. 2022) decided to call a machine that works under this model as \(\mathsf{QRAM}\): quantum random-access machine. The formal definition of an \(m\)-sparse quantum algorithm with a \(\mathsf{QRAG}\) is the following:
Definition 3.11 (Sparse QRAG algorithm (Buhrman et al. 2022)) Let \(\mathcal{C} = (n,T, W, M, C_1, \ldots, C_T)\) be a \(\mathsf{QRAG}\) algorithm using time \(T\), \(W\) work qubits, and \(M\) memory qubits. Then, we say that \(C\) is \(m\)-sparse, for some \(m \le M\), if at every time-step \(t \in \{0, \ldots, T\}\) of the algorithm, the state of the memory qubits is supported on computational basis vectors of Hamming weight \(\le m\). i.e., we always have
\[\begin{equation} |\psi_t\rangle \in \text{span} \left( |u\rangle|v\rangle \;\middle|\; u \in \{0,1\}^W, v \in \binom{[M]}{\le m} \right) \end{equation}\]
In other words, if \(|\psi_t\rangle\) is written in the computational basis: \[\begin{equation} |\psi_t\rangle=\sum_{u \in \{0,1\}^W} \sum_{v \in \{0,1\}^M} \alpha^{(t)}_{u,v} \cdot \underbrace{|u\rangle}_{\text{Work qubits}}\otimes \underbrace{|v\rangle}_{\text{Memory qubits}}, \end{equation}\]
then \(\alpha^{(t)}_{u,v} = 0\) whenever \(|v| > m\), where \(|v|\) is the Hamming weight of \(v\).
Now that we have seen sparse \(\mathsf{QRAG}\) algorithms, we can look at how memory compression is performed. In particular, any \(m\)-sparse quantum algorithm running in time \(T\) and utilizing \(M\) memory qubits can be simulated up to an additional error \(\epsilon\) by a quantum algorithm running in time \(O(T \log (\frac{T}{\epsilon})\log(M))\) using \(O(m\log(M))\) qubits.
Theorem 3.2 (Memory compression for m-sparse QRAG algorithms (Buhrman et al. 2022)) Let \(T\), \(W\), \(m < M = 2^\ell\) be natural numbers, with \(M\) and \(m\) both powers of \(2\), and let \(\epsilon \in [0, 1/2)\). Suppose we are given an \(m\)-sparse \(\mathsf{QRAG}\) algorithm using time \(T\), \(W\) work qubits and \(M\) memory qubits, that computes a Boolean relation \(F\) with error \(\epsilon\).
Then we can construct a \(\mathsf{QRAG}\) algorithm which computes \(F\) with error \(\epsilon' > \epsilon\), and runs in time \(O(T \cdot \log(\frac{ T}{\epsilon' - \epsilon}) \cdot \gamma)\), using \(W + O(\log M)\) work qubits and \(O(m \log M)\) memory qubits.
3.3 Implementations
In this section we’ll be creating oracles that can perform the encodings that were presented in section 3.1. Of the presented oracles only 3 will make use of the quantum memory device introduced in definition 3.6: the bucket brigade, KP-trees and the block encoding from data structure. It is interesting to note that these oracles actually aid each other. In fact, KP-trees rely on the existence of a \(\mathsf{QMD}\) that can perform binary encoding and similarly block encoding from data structures requires the existence of a \(\mathsf{QMD}\) that can perform amplitude encoding. The other oracles will either make use of specific properties of the input data, such as sparsity, or will encode a probability distribution as a quantum state. The key insight lies in the fact that all oracles, with or without \(\mathsf{QMD}\), have a constant complexity which allows us to work in the quantum memory model of computation of definition 3.4. All the presented oracles with their interconnection can be seen in figure 3.2, where the oracle which require a \(\mathsf{QMD}\) have been indicated with a *.
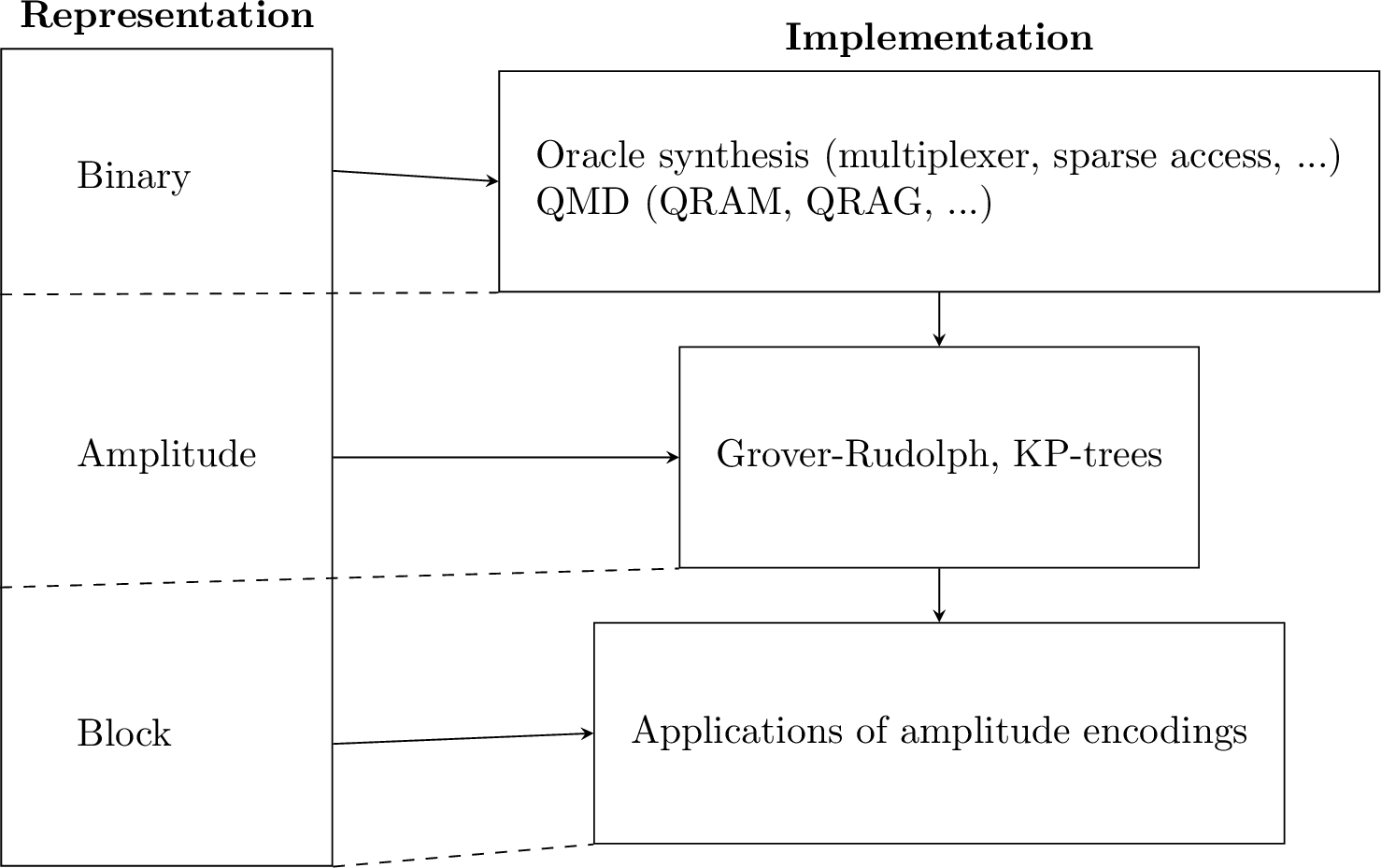
Figure 3.2: This figure shows the different types of data encoding techniques with the corresponding oracles. The vertical lines on the right hand side indicate (possible) dependencies between oracles.
3.3.1 Binary encoding
In this section we are discussing implementations a unitary giving query access to a list of \(m\)-bits values. A possible way of reading this section is throught the lenses of finding the “best” gate decomposition of that unitary, which has the following form:
\[\begin{equation} U = \sum_{i=0}^{N-1} |i\rangle\langle i| \otimes U_i = \begin{bmatrix} U_0 & & & \\ & U_1 & & \\ & & \ddots & \\ & & & U_{N-1} \end{bmatrix}, \tag{3.10} \end{equation}\]
where \(U_i|0\rangle=|x_i\rangle\) and \(x_i \in \{0,1\}^m\). Importantly, when considering gate decompositions of this unitary, we are allowed to act in a larger space, as long as in the subspace of interested our application acts accoring to Eq.(3.10).
3.3.1.1 Oracle synthesis
As we briefly anticipated in Section 2.3, if we know a function that maps \(x_i = f(i)\) we can create a circuit for getting query access to \(x_i\). If our data is represented by the output of a function, we can consider these techniques for data loading.
The idea of creating a quantum circuit from a classical Boolean function is relatively simple and can be found in standard texts in quantum computation ((Nielsen and Chuang 2002) or the this section on the Lecture notes of Dave Bacon). There is a simple theoretical trick that we can use to see that for any (potentially irreversible) Boolean circuit there is a reversible version for it. This observation is used to show that non-reversible circuits are not more powerful than reversible circuits. To recall, a reversible Boolean circuit is just bijection between domain and image of the function. Let \(f : \{0,1\}^m \mapsto \{0,1\}^n\) be a Boolean function (which we assume is surjective, i.e. the range of \(f\) is the whole \(\{0,1\}^n\)). We can build a circuit \(f' : \{0,1\}^{m+n} \mapsto \{0,1\}^{m+n}\) by adding some ancilla qubits, as it is a necessary condition for reversibility that the dimension of the domain matches the dimension of the range of the function. We define \(f'\) as the function performing the mapping \((x, y) \mapsto (x, y \oplus f(x))\). It is simple to see by applying twice \(f'\) that the function is reversible (check it!).
Now that we have shown that it is possible to obtain a reversible circuits from any classical circuit, we can ask: what is an (rather inefficient) way of getting a quantum circuit? Porting some code (or circuit) from two similar level of abstraction is often called transpiling. Again, this is quite straightforward (Section 1.4.1 (Nielsen and Chuang 2002)). Every Boolean circuit can be rewritten in any set of universal gates, and as we know, the NAND port is universal for classical computation. It is simple to see (check the exercise) that we can use a Toffoli gate to simulate a NAND gate, so this gives us a way to obtain a quantum circuit out of a Boolean circuit made of NAND gates. With these two steps we described a way of obtaining a quantum circuit from any Boolean function \(f\).
Exercise 3.4 (Toffoli as NAND) Prove that a Toffoli gate, along with an ancilla qubit, can be used to obtain a quantum version of the NAND gate?
However, an application of the quantum circuit for \(f\), will result in a garbage register of some unwanted qubits. To get rid of them we can use this trick:
\[\begin{equation} |x\rangle|0\rangle|0\rangle|0\rangle \mapsto |x\rangle|f(x)\rangle|k(f, x)\rangle|0\rangle\mapsto |x\rangle|f(x)\rangle|k(f, x)\rangle|f(x)\rangle \mapsto |x\rangle|f(x)\rangle. \tag{3.11} \end{equation}\]
Let’s explain what we did here. In the first step we apply the circuit that computes \(f'\). In the second step we perform a controlled NOT operation (controlled on the third and targeting the fourth register), and in the last step we undo the application of \(f'\), thus obtaining the state \(|x\rangle|f(x)\rangle\) with no garbage register.
Importantly, the idea of obtaining a quantum circuit from a classical reversible circuit is not practical, and is only relevant didactically. The task of obtaining an efficient quantum circuit from a Boolean function is called “oracle synthesis”. Oracle synthesis is far from being a problem of only theoretical interest, and it has received a lot of attention in past years (Soeken et al. 2018) (Schmitt et al. 2021) (Shende, Bullock, and Markov 2006). Today software implementations can be easily found online in most of the quantum programming languages/library. For this problem we can consider different scenarios, as we might have access to the function in form of reversible Boolean functions, non-reversible Boolean function, or the description of a classical circuit. The problem of oracle syntheses is a particular case of quantum circuit synthesis (Table 2.2 of (Brugière 2020) ) and is a domain of active ongoing research.
If we want to prove the runtime of a quantum algorithm in terms of gate complexity (and not only number of queries to an oracle computing \(f\)) we need to keep track of the gate complexity of the quantum circuits we use. For this we can use the following theorem.
Theorem 3.3 ((Buhrman, Tromp, and Vitányi 2001) version from (Bausch, Subramanian, and Piddock 2021)) For a probabilistic classical circuit with runtime \(T(n)\) and space requirement \(S(n)\) on an input of length \(n\) there exists a quantum algorithm that runs in time \(O(T(n)^{\log_2(3)}\) and requires \(O(S(n)\log(T(n))\) qubits.
3.3.1.2 Sparse access
Sparse matrices are very common in quantum computing and quantum physics, so it is important to formalize a quantum access for sparse matrices. This model is sometimes called in literature “sparse access” to a matrix, as sparsity is often the key to obtain an efficient circuit for encoding such structures without a \(\mathsf{QRAM}\). Of course, with a vector or a matrix stored in a \(\mathsf{QRAM}\), we can also have efficient (i.e. in time \(O(\log(n))\) if the matrix is of size \(n \times n\)) query access to a matrix or a vector, even if they are not sparse. It is simple to see how we can generalize query access to a list or a vector to work with matrices by introducing another index register to the input of our oracle. For this reason, this sparse access is also called quite commonly “query access”.
Definition 3.12 (Query access to a matrix) Let \(V \in \mathbb{R}^{n \times d}\). There is a data structure to store \(V\), (where each entry is stored with some finite bits of precision) such that, a quantum algorithm with access to the data structure can perform \(|i\rangle|j\rangle|z\rangle \to |i\rangle|j\rangle|z \oplus v_{ij}\rangle\) for \(i \in [n], j \in [d]\).
A matrix can be accessed also with another oracle.
Definition 3.13 (Oracle access in adjacency list model) Let \(V \in \mathbb{R}^{n \times d}\), there is an oracle that allows to perform the mappings:
- \(|i\rangle\mapsto|i\rangle|d(i)\rangle\) where \(d(i)\) is the number of non-zero entries in row \(i\), for \(i \in [n]\), and
- \(|i,l\rangle\mapsto|i,l,\nu(i,l)\rangle\), where \(\nu(i,l)\) is the \(l\)-th nonzero entry of the \(i\)-th row of \(V\), for \(l \leq d(i)\).
The previous definition is also called adjacency array model. The emphasis is on the word array, contrary to the adjacency list model in classical algorithms (where we usually need to go through all the list of adjacency nodes for a given node, while here we can query the list as an array, and thus use superposition) (Dürr et al. 2004).
It is important to recall that for Definition 3.12 and 3.13 we could use a \(\mathsf{QRAM}\), but we also expect not to use a \(\mathsf{QRAM}\), as there might be other efficient circuit for performing those mapping. For instance, when working with graphs (remember that a generic weighted and directed graph \(G=(V,E)\) can be seen as its adjacency matrix \(A\in \mathbb{R}^{|E| \times |E|}\)), many algorithms call Definition 3.12 vertex-pair-query, and the two mappings in Definition 3.13 as degree query and neighbor query. When we have access to both queries, we call that quantum general graph model (Hamoudi and Magniez 2018). This is usually the case in all the literature for quantum algorithms for Hamiltonian simulation, graphs, or algorithms on sparse matrices.
3.3.1.3 Circuits
TODO
What if we want to use a quantum circuit to have quantum access to a vector of data? In this section we are going to describe few circuits for the task, each showcasing different properties and trade-offs between depth and space. For example the simplest circuit that we can come up with, has a depth that is linear in the length of the vector. This kind of circuit is often used in literature, e.g. for computing functions using space-time trade-offs (Krishnakumar et al. 2022; Gidney and Ekerå 2021). This circuit (which sometimes goes under the name QROM, or circuit for table lookups (Hann et al. 2021), or multiplexer, is simply a series of multi-control operations, each of which is writing (using \(X\) gates) some binary string on the target register. Controlled on the index register being in the state \(|0\rangle\), we write in the output register the value of our vector in position \(x_0\), controlled in the index register being \(|1\rangle\), we write on the output register the value of our vector in position \(x_1\), etc.. This will result in a circuit with a depth that is linear in the length of the vector that we are accessing, however this circuit won’t require any ancilla qubit. We will discuss more some hybrid architecture that allows a trade off between depth and ancilla qubits in Section ??. The Toffoli count of this circuit can be improved in various ways (Babbush et al. 2018; Zhu, Sundaram, and Low 2024). Importantly, the depth of this circuit depends on the number of oracle entries \(N\), and in simple implementations depends also linearly in \(m\). As an example, consider the following circuit.
![This is the example of a multiplexer circuit for the list of values x=[1,1,0,1]. Indeed, if we initialize the first two qubits with zeros, the output of the previous circuit will be a 1 in the third register, and so on.](images/multiplexer.png)
Figure 3.3: This is the example of a multiplexer circuit for the list of values x=[1,1,0,1]. Indeed, if we initialize the first two qubits with zeros, the output of the previous circuit will be a 1 in the third register, and so on.
The most general version of the circuit is the following, which includes some optimization.
![The implementation of the multiplexer of [@babbush2018encoding]. Importantly, only one $T$ gate is required to write in the target register a single memory entry. The memory entry is written using a Fan-Out gate (which can be decomposed into CNOT gates. Note that the depth of the circuit is linear in the number of memory entries.The angular lines in the gates are representing the so-called 'logical-AND', which is a CCNOT gate targeting an ancilla qubit starting in a particular state (ground state on which we apply a $T$ gate) and gets uncomputed using measurament-based uncomputation.](algpseudocode/decomposedlookups.png)
Figure 3.4: The implementation of the multiplexer of (Babbush et al. 2018). Importantly, only one \(T\) gate is required to write in the target register a single memory entry. The memory entry is written using a Fan-Out gate (which can be decomposed into CNOT gates. Note that the depth of the circuit is linear in the number of memory entries.The angular lines in the gates are representing the so-called ‘logical-AND’, which is a CCNOT gate targeting an ancilla qubit starting in a particular state (ground state on which we apply a \(T\) gate) and gets uncomputed using measurament-based uncomputation.
The bucket brigade architecture (in short BB architecture) is another possible architecture. This protocol was originally developed to be implemented with qutrits (Giovannetti, Lloyd, and Maccone 2008b) but recent work has shown it can be implemented with qubits as well (Hann et al. 2021). First, we will mention the idea with qutrits since it is more intuitive to understand. Again, using the terminology introduced in definition 3.6, we’ll have: an address register, a target register (which will be referred to as a bus register) and a memory register. The input will be a vector of binary numbers \(X \in (\{0,1\}^m)^n\) and the aim is to load a specific entry \(X_i \in \{0,1\}^m\) on the bus register.
The BB protocol will use the memory register in such a way that it has access to tree like structure. The tree saves the entries of \(X\) in the leaves, which are referred to as memory cells. Each memory cell is connected to a parent node which form a set of intermediate nodes up until the root of the tree. Each intermediate node (up to the root) is called a quantum router (Figure 1b of (Hann et al. 2021)) and is a qutrit (i.e., a three level quantum system), which can be in state \(|0\rangle\) (route left), \(|1\rangle\) (route right), and \(|W\rangle\) (wait).
When we want to perform a query, we prepare the address register with the index of the memory cell that we want to reach and we set all the router registers to the \(|W\rangle\) state. Conditioned on the first qubit of the address register, the root of the tree changes from \(|W\rangle\) to either \(|0\rangle\)(left) or \(|1\rangle\)(right). This is followed by a similar operation which uses as control the second qubit of the address register to change the state of the next node in the tree to either \(|0\rangle\) or \(|1\rangle\). The process of changing the state of the routers is repeated until the last layers of the tree(i.e. the memory cell) is reached. Now, the memory register will be in the state of the binary number \(X_i\). This can be copied to the bus register by simply applying a series of CNOT gates (and thus we do not violate the no-cloning theorem).
Studying an error model of the BB architecture is hard. An attempt was first made in (Arunachalam et al. 2015) which gave initial, but rather pessimistic result. More recently, a series of developments in (Hann et al. 2021) and (Hann 2021) (accessible here) have shone light on the noise resilience of the BB \(\mathsf{QRAM}\). The results presented in these more recent works are much more positive. Some resource estimations can be found in (Di Matteo, Gheorghiu, and Mosca 2020), which do not take into account the new developements in the study of the error.
The metric of choice to test whether a quantum procedure has faithfully recreated a desired state is the fidelity \(F\), with the infidelity defined as \(1-F\). Given a addressable memory of size \(N\)(i.e. \(\log N\) layers in the binary tree) and a bucket brigade which requires \(T\) time-steps with a probability of error per time step of \(\epsilon\), the infidelity of the bucket brigade scales as:
\[\begin{equation} 1-F \approx \sum_{l=1}^{\log N} (2^{-l}) \epsilon T2^{l} = \epsilon T \log N, \tag{3.12} \end{equation}\]
Exercise 3.5 Calculate \(\sum_{l=1}^{\log N} l\)
The time required to perform a query, owing to the tree structure of the BB, is \(T=O(\log N)\). This can be seen trivially from the fact that \(T \approx \sum_{l=0}^{\log N -1 } l = \frac{1}{2}(\log N)(\log N +1)\), but can be decreased to \(O(\log N)\) (Appendix A of (Hann et al. 2021)). This leaves us with the sought-after scaling of the infidelity of \(\widetilde{O}(\epsilon)\) where we are hiding in the asymptotic notation the terms that are polylogarithmic in \(N\). The error that happen with probability \(\epsilon\) can be modeled with Kraus operators makes this error analysis general and realistic (Appendix C (Hann et al. 2021)), and is confirmed by simulations. For a proof of Equation (3.12) see Section 3 and Appendix D of (Hann et al. 2021).
![A possible implementation of the bucket-brigade QRAM in the circuit model, from [@hann2021resilience]](algpseudocode/circuit_bb.png)
Figure 3.5: A possible implementation of the bucket-brigade QRAM in the circuit model, from (Hann et al. 2021)
![A possible implementation of the bucket-brigade QRAM in the circuit model, from [@doriguello2024practicality;@arunachalam2015robustness]. In every layer, before the parallel layer of Toffoli gates, a log-depth linear-size gadget is copying the index register. In this way, the Toffoli gates can be executed in parallel.](algpseudocode/circuit_bb_ccnots.png)
Figure 3.6: A possible implementation of the bucket-brigade QRAM in the circuit model, from (Joao F. Doriguello et al. 2024; Arunachalam et al. 2015). In every layer, before the parallel layer of Toffoli gates, a log-depth linear-size gadget is copying the index register. In this way, the Toffoli gates can be executed in parallel.
Exercise 3.6 The last block of the circuit depicted in Figure 3.6 has linear depth in the number of memory elements, i.e. has exponential depth in the number of qubits in the index regsiter. Eventually using some ancilla qubits, can you create a gadget that writes to the output register in logarithmic depth?
The following statement gives a resource estimation for a QRAM of logarithmic depth using the quantum architecture proposed in (Litinski and Nickerson 2022).
Lemma 3.1 (Complexity of QRAM using (Joao F. Doriguello et al. 2024)) One bucket-brigade \(\mathsf{QRAM}\) call of size \(2^n\) and precision \(\kappa\) requires (already including its uncomputation) \(2^n - 2\) \(\mathsf{Toffoli}\) gates, \(2^{n+1} - n - 1\) dirty ancillae (plus \(n+\kappa\) input/output qubits), and has \(\mathsf{Toffoli}\)-width of \(2^{n-1}\), reaction depth of \(2(n-1)\), and active volume of \((25 + 1.5\kappa + C_{|CCZ\rangle})2^n\).
In the following, we report the resource count of some \(\mathsf{QRAM}\) constructions using different techniques.
Theorem 3.4 (Complexity of QRAM using Fourier analysis (Allcock et al. 2023)) Let \(n\in\mathbb{N}\) be a power of \(2\). A \(\mathsf{QRAM}\) of memory size \(n\) can be implemented in \(O(1)\)-depth using
- either \(\frac{1}{2}n^2\log{n} + O(n^2)\) ancillae and \(2n^2 + O(n\log{n})\) Fan-Out gates with arity \(\leq 1+n^2\),
- or \(2n^2\) ancillae and \(2\) \(\mathsf{GT}\) gates with arity \(\leq \frac{1}{2}n^2\log{n} + O(n^2)\).
Theorem 3.5 (Complexity of QRAM using one-hot encoding ideas (Allcock et al. 2023)) For every \(n \in \mathbb{N}\) a power of \(2\), a \(\mathsf{QRAM}\) of memory size \(n\) can be implemented in \(O(1)\)-depth using
- either \(2n\log{n}\log\log{n} + O(n\log{n})\) ancillae and \(6n\log{n} + O(n\log\log{n})\) Fan-Out gates with arity \(\leq n+1\),
- or \(3n\log{n} + O(n\log\log{n})\) ancillae and \(6\) \(\mathsf{GT}\) gates with arity \(\leq n\log{n} + O(n\log\log{n})\).
Theorem 3.6 (Complexity of QRAM using recursive tricks (Allcock et al. 2023)) For every \(n,d \in \mathbb{N}\), a \(\mathsf{QRAM}\) of memory size \(n\) can be performed in \(O(d)\)-depth~using
- either \(O(n\log^{(d)}{n}\log^{(d+1)}{n})\) ancillae and \(O(n\log^{(d)}{n})\) Fan-Out gates,
- or \(O(n\log^{(d)}{n})\) ancillae and \(16d-10\) \(\mathsf{GT}\) gates.
3.3.2 Amplitude encoding
We now move our attention to amplitude encoding, which was first introduced in section 3.1.2. In amplitude encoding, we encode a vector of numbers in the amplitude of a quantum state. Implementing a quantum circuit for amplitude encoding can be seen as preparing a specific quantum states, for which we know the amplitudes. In other words, this is actually a state preparation problem in disguise, and we can use standard state preparation methods to perform amplitude encoding. However, note that amplitude encoding is a specific example of state preparation, when the amplitudes of the state are known classically or via an oracle. There are other state preparation problems that are not amplitude encoding, like ground state preparation, where the amplitudes of the quantum state is not known and only the Hamiltonian of the system is given. In the following, we briefly discuss the main techniques developed in the past decades for amplitude encoding.
What are the lower bounds for the size and depth complexity of circuits performing amplitude encoding? Since amplitude encoding can be seen as a quantum state preparation, without assuming any kind of oracle access, we have a lower bound of \(\Omega\left(2^n\right)\) (Plesch and Brukner 2011; Shende, Markov, and Bullock 2004). For the depth, we have a long history of results. For example, there is a lower bound of \(\Omega(\log n)\) that holds for some states (and hence puts a lower bound on algorithms performing generic state preparation ) using techniques from algebraic topology (Aharonov and Touati 2018). Without ancilla qubits (Plesch and Brukner 2011) proposed a bound of \(\Omega(\frac{2^n}{n})\). The bound on the depth has been refined to a \(\Omega(n)\), but only when having arbitrarily many ancilla qubits (X.-M. Zhang, Yung, and Yuan 2021). The more accurate bound is of \(\Omega\left( \max \{n ,\frac{4^n}{n+m} \} \right )\) (Theorem 3 of (X. Sun et al. 2023)), where \(m\) is the number of ancilla qubits. The algorithms of (Yuan and Zhang 2023), which we discuss later, saturates this bound.
We can also study the complexity of the problem in the oracle model. For example, if we assume an oracle access to \(f : \{0,1\}^n \mapsto [0,1]\), using amplitude amplification techniques on the state \(\sum_x |x\rangle\left(f(x)|0\rangle + \sqrt{1-f(x)}|1\rangle \right)\), there is a quadratic improvement in the number of queries to the oracle, yielding \(\widetilde{O}(\sqrt{N})\) complexity (L. K. Grover 2000), where \(N = 2^n\). This can be seen if we imagine a vector with only one entry with the value \(1\), where the number of queries to amplify the subspace associated with the rightmost qubit scales with \(\sqrt{N}\). Few years later, we find another work by (L. Grover and Rudolph 2002) which, under some mildly stronger assumptions improved the complexity of the algorithms for a very broad class of states. This algorithm is better discussed in Section 3.3.2.1.
Alternatively, we can assume a direct oracle access to the amplitudes (Sanders et al. 2019). Under this assumption, we have access to an oracle storing the \(i\)th amplitude \(\alpha_i\) with \(n\) bits, (actually, they use a slightly different model, where the oracle for the amplitude \(\alpha_i\) is \(|i\rangle|z\rangle\mapsto |i\rangle|z \oplus \alpha_i^{(n)}\rangle\) where \(\alpha_i^{(n)}=\lfloor 2^n\alpha_i \rfloor\)). Ordinarily, the circuit involves the mapping \(|i\rangle|\alpha_i^{(n)}\rangle|0\rangle \mapsto |i\rangle|\alpha_i\rangle \left(\sin(\theta_i)|0\rangle + \cos(\theta_i)|1\rangle\right)\), which requires control rotations and arithmetic circuits to compute the angles \(\theta_i = \arcsin(\alpha_i/2^n)\). However, by substituting the arithmetic circuit by a comparator operator (Gidney 2018; Cuccaro et al. 2004; Luongo et al. 2024), the circuit can be implemented either with \(2n\) non-Clifford gates or \(n\) non-Clifford gates and \(n\) ancilla qubits. This scheme can even be extended to encode complex amplitudes in both Cartesian and polar forms, or apply to the root coefficient problem of real amplitudes, where we have an oracle access to the square of the amplitude \(\alpha_i^2\) instead of \(\alpha_i\). For positive or complex amplitudes, this algorithm involves \(\frac{\pi}{4}\frac{\sqrt{N}}{\|\alpha\|_2}\) exact amplitude amplifications, so it has a runtime of \(\frac{\pi}{4}\frac{t\sqrt{N}}{\|\alpha\|_2} + O(1)\) non-Clifford gates, where \(t\) is the number of bits of precision used to specify an amplitude (the authors preferred to count the number of non-Clifford gates, as they are the most expesive one to implement in (most of) the error corrected architectures, and serves as a lower bound for the size complexity of a circuit. For the root coefficient problem, the runtime becomes \(\frac{\pi}{4} \frac{n\sqrt{N}}{\|\alpha\|_1} + O\left(n \log \left(\frac{1}{\epsilon}\right)\right)\) non-Clifford gates. For certain sets of coefficients, this model can further be improved to reduce the number of ancilla qubits needed per bits of precision from a linear dependence (Sanders et al. 2019) to a log dependence (Table 2 of (Bausch 2022)). Also the work of (McArdle, Gilyén, and Berta 2022) works assuming an oracle returning the amplitudes of the state we want to build \(\frac{1}{\mathcal{N}_f}\sum_{x=0}^{N-1}f(x)|x\rangle\) (where \(\mathcal{N}_f\) is the usual normalization factor), and does not use arithmetic, and uses \(O(\frac{n d_\epsilon}{\mathcal{F}_{\widetilde{f}^{[N]}} })\) (where \(\widetilde{f}^{[N]}\) is called “discretized \(\ell_2\)-norm filling-fraction”, and \(d_\epsilon\) is the degree of a polynomial approximation that depends on \(\epsilon\), the approximation error in the quantum state ) and uses only \(4\) ancilla qubits.
Instead of treating the problem as a state preparation problem, we can also perform amplitude encoding using multivariable quantum signal processing (M-QSP) (See Chapter ??). The principle behind this method is to interpret the amplitude of a quantum state as a function of a multivariable polynomial (McArdle, Gilyén, and Berta 2022; Mori, Mitarai, and Fujii 2024; Rosenkranz et al. 2024). Particularly, using Linear Combination of Unitaries techniques, we can approximate the quantum state as a multivariable function by a truncated Fourier or Chebyshev series (Rosenkranz et al. 2024). The truncated Fourier series approximation requires \(O(d^D + Dn \log d)\) two-qubit gates, while the truncated Chebyshev series approximation requires \(O(d^D + Ddn \log n)\) two-qubit gates, where \(D\) is the number of dimensions and \(d\) is the degree of the polynomial used in the approximation. The number of qubits in both techniques scales as \(O(Dn + D \log d)\). The exponential dependence in \(D\) can further be improved by the following theorems.
Theorem 3.7 (Bivariate state preparation (Mori, Mitarai, and Fujii 2024)) Given a Fourier series \(f\) of degree \((d_1, d_2)\) that can be constructed with M-QSP, we can prepare a quantum state \(|\psi_f\rangle\) using \(O((n_1d_1 + n_2d_2)/\mathcal{F}_f)\) gates, where \(\mathcal{F}_f = \mathcal{N}_f/( \sqrt{N_1N_2}|f|_{max})\), \(\mathcal{N}_f = \sqrt{\sum_{i,j} (f(x_1^{(i)}), f(x_2^{(j)}) )}\), whereas \(n_1\) and \(n_2\) are the number of bits used to specify the value of the variable \(x_1\) and \(x_2\), respectively.
Theorem 3.8 (Multivariate state preparation (Mori, Mitarai, and Fujii 2024)) Given a Fourier series \(f\) of degree \((d_1, \dots, d_D)\) that can be constructed with multivariate quantum signal processing, we can prepare a quantum state \(|\psi_f\rangle\) using \(O(n d D/\mathcal{F}_f)\) gates, where \(n=\max (n_1, \dots, n_D)\) and \(d=\max (d_1, \dots, d_D)\)
Meanwhile, if trade-offs are allowed for state preparation, we can further improve the complexity of the algorithm. For example, we can build a state over \(n\) qubits with depth \(\widetilde{O}\left(\frac{2^n}{m+n} +n\right)\) and size \(\widetilde{O}\left(2^n \right)\) if we have \(m\) available ancillas (X. Sun et al. 2023). On the other hand, we can reduce the number of \(T\)-gates to \(O(\frac{N}{\lambda} + \lambda \log \frac{N}{\epsilon}\log \frac{\log N}{\epsilon})\) if we allow a tunable number of \(\lambda \frac{\log N}{\epsilon}\) dirty qubits (Low, Kliuchnikov, and Schaeffer 2018). A dirty qubit is an auxiliary qubit that is left entangled with another register at the end of computation. It cannot be reused by subsequent computations without being disentangled, but can be uncomputed using measurement-based uncomputation tricks.
In addition to the algorithms (X. Sun et al. 2023; Rosenthal 2021), trade-offs can introduce additional circuits that can achieve the lower bound of the depth complexity. For example, using \(O \left(2^n\right)\) ancilla qubits, we can perform amplitude encoding with circuit depth \(\Theta \left( n \right)\), which further relaxes the connectivity requirements for M-QSP (X.-M. Zhang, Li, and Yuan 2022). This technique also improves upon sparse state preparation, with a circuit depth \(\Theta \left( \log k N \right)\), where \(k\) is the sparsity. This represents an exponential improvement in circuit depth over previous works (Gleinig and Hoefler 2021; Veras, Silva, and Silva 2022). This leads to a deterministic algorithm that achieves the lower bounds in circuit depth if we allow \(m\) ancilla qubits, which is summarized in the following theorem.
Theorem 3.9 (Circuit for controlled state preparation (Theorem 1 of (Yuan and Zhang 2023)) ) For any \(k \in \mathbb{N}\) and quantum states \(\{ |\psi_i\rangle | i \in \{0,1\}^k \}\) there is a circuit performing \[ |i\rangle|0\rangle \mapsto |i\rangle|\psi_i\rangle, \forall i \in \{0,1\}^k, \] which can be implemented by a circuit of depth \(O(n + k + \frac{2^{n+k}}{n+k+m})\) and size \(O(2^{n+k})\) with \(m\) ancillary qubits. These bounds are optimal for any \(m,k \geq 0\).
Theorem 3.10 (Circuit for state preparation (Theorem 2 of (Yuan and Zhang 2023)) ) For any \(m > 0\), any \(n\)-qubit quantum state \(|\psi_v\rangle\) can be generated by a quantum circuit using single qubit gates and CNOT gates, of depth \(O(n+ \frac{2^n}{n+m}\)) and size \(O(2^n)\) with \(m\) ancillary qubits. These bounds are optimal for any \(m \geq 0\).
There are also other trade-off techniques that can be used, like probabilistic state preparation via measurements (X.-M. Zhang, Yung, and Yuan 2021) or approximate state preparation problem (Z. Zhang, Wang, and Ying 2024). However, these techniques are beyond the scope of this chapter and will not be discussed. Interested readers can refer to the respective articles. However, even if we allow intermediate measurements we have lower bounds on the T-count, which is reached by the algorithm of (Gosset, Kothari, and Wu 2024).
Theorem 3.11 (Quantum state preparation with optimal T-count (Gosset, Kothari, and Wu 2024)) Any \(n\)-qubit state can be prepared up to error \(\epsilon\) by a Clifford+T circuit starting with the all-zeroes state using \[O\left(\sqrt{2^n\log(1/\epsilon)} + \log(1/\epsilon)\right)\] \(T\) gates and ancillas. Furthermore, no Clifford+T circuit (even with measurement and adaptivity) can use asymptotically fewer \(T\)-gates.
In summary, there are many methods to perform amplitude encoding, each with different complexities through various trade-offs. In general, the data set that can be encoded using amplitude encoding lies under two main categories: (i) those discrete data that come from a vector or a matrix, or (ii) those that come from a discretized probability distribution. In literature, amplitude encoding of vectors or matrices is called state preparation via a KP-tree, while amplitude encoding of discretized probability distribution is called Grover-Rudolph (GR) state preparation (L. Grover and Rudolph 2002). The main difference between the KP-tree method and the GR state preparation is that the KP-tree method requires a quantum memory to store some precomputed values in a data structure or a tree, while the GR state preparation does not require a quantum memory. In fact, GR state preparation is designed such that there are efficient circuits to implement the oracle in the quantum computer using 3.3.1.1.
| Method | Size | Ancilla | Depth | Function type | |
|---|---|---|---|---|---|
| 1 | M-SQP | \(O(\frac{ndD}{\mathcal{F}})\) | 1 | ||
| 2 | GR | \(O(nT_{oracle})\) | \(O(t_{oracle})\) | log | Eff. int. |
| 3 | Adiabatic | \(O(\frac{T_{oracle}}{\mathcal{F}^4})\) | \(O(t_{oracle})\) | - | Arb. |
| 4 | Black-box | \(O(\frac{T_{oracle}}{\mathcal{F}})\) | \(O(t_{oracle})\) | - | Arb. |
| 5 | FSL | \(O(d^D + Dn^2)\) | 0 | - | Arb. |
| 6 | LCU-based | \(O(d^D + Dn\log d)\) | \(O(D \log d)\) | - | Arb. |
| 7 | Circuit | \(N\log\left(\frac{N}{\epsilon}\right)\)* | \(O(n)\) | \(N\log\left(\frac{N}{\epsilon}\right)\)* | Arb. |
| 8 | Circuit | \(N\log\left(\frac{N}{\epsilon}\right)\) | \(O\left(n+\lambda \right)\) | \(\frac{N}{n + \lambda}\log \left(\frac{N}{\epsilon}\right) + n\log\left(\frac{N}{\epsilon}\right)\) * | Arb. |
| 9 | Circuit | \(O\left(\sqrt{2^n\log(\frac{1}{\epsilon})} + \log(\frac{1}{\epsilon})\right)\)* | \(O\left(\sqrt{2^n\log(\frac{1}{\epsilon})} + \log(1/\epsilon)\right)\) | ? | Arb. |
By looking at different models of quantum computation, we find that state preparation can be performed in constant depth assuming unbounded Fan-Out circuits (Corollary 4.2) (Rosenthal 2021). The key idea behind this work was to link state preparation to a DNF (disjunctive normal form) boolean formula, which is evaluated in the quantum algorithm. Compiling Fan-Out gates using CNOT gates, this leads to a circuit of depth \(O(n)\) and \(O(n2^n)\) ancillas. State preparation can also be studied under a different lens in complexity theory, leading to new interesting insights. For example, people studied the complexity of generating quantum states (Rosenthal and Yuen 2021; Metger and Yuen 2023). For example, the states that can be generated by a (space-uniform) polynomial-sized quantum circuit, forms the class of \(\mathsf{StatePSPACE}\). This class has been proven to be equivalent to \(\mathsf{StateQIP}\) (the class of states that a polynomial-time quantum verifier can generate with interactions with a all-powerful and untrusted quantum prover), echoing the equivalence between the complexity classes \(\mathsf{QIP}\) and \(\mathsf{PSPACE}\).
There are many other works in state preparation, and we refer the interested reader to (Bergholm et al. 2005; Plesch and Brukner 2011, 2011; Araujo et al. 2021; Bausch 2022; Rattew and Koczor 2022; Rosenthal 2021, 2024; X.-M. Zhang, Li, and Yuan 2022; Buhrman et al. 2023a; Gleinig and Hoefler 2021; Holmes and Matsuura 2020; Moosa et al. 2023; Z. Zhao et al. 2021). Now we consider two very didactic and general models of quantum state preparation. The former is known as Grover-Rudolph state preparation (L. Grover and Rudolph 2002) whilst the latter is known as a state prepration via a precomputed data structure that is quantum accessible, called KP-tree. A difference between the Grover-Rudolph and the KP-tree method is that GR is assuming a query access to an oracle which does not need to be necessarily needs to be implemented with a quantum memory. While the KP-tree method assumes some precomputation of a data structure (a tree) which is specifically stored into the QRAM. In fact, for the kinds of quantum states that GR was designed to create, there are efficient circuits for the implementing the oracle, that can be implemented in a quantum computer using Section3.3.1.1. For both, the total depth of the circuit (considering the QMD as part of the quantum computer) is \(O(\log^2(N))\), while the size of the circuit is \(O(N\log N)\).
Finally we note that in (Prakash 2014) (Section 2.2.1), Prakash shows subroutines for generating \(|x\rangle\) for a sparse \(x\) in time \(O(\sqrt{\|x\|_0})\).
In this model is it possible to prepare states with long-range entanglement with only constant quantum-depth and logarithmic classical depth. However, the authors do not generalize their algorithm for state preparation for any quantum state, but only for a restricted class of quantum states with constraints on the Hamming weights.
3.3.2.1 Grover-Rudolph state preparation, its problems, and the solutions
In (L. Grover and Rudolph 2002) the authors discussed how to efficiently create quantum states proportional to functions satisfying certain integrability condition, i.e. the function considered must be square-integrable. An example of functions with this properties are log-concave probability distributions. Let \(p(x)\) be a probability distribution over \(\mathbb{R}\). We denote by \(x_i^n\) is the points of the discretization over the domain, i.e \(x_i^{(n)} = -w + 2w \frac{i}{2^n}\) for \(i=0,\dots,2^n\), and \([-w,w]\) is the window of discretization, for a constant \(w\in\mathbb{R}_+\). In this case, \(n\) acts as the parameter that controls how coarse or fine is the discretization. Consider referencing the appendix for more informations about measure theory and probability distributions. We want to create the quantum state
\[\begin{equation} |\psi_n\rangle = \sum_{i=0}^{2^n-1}\sqrt{p^{(n)}_i}|i\rangle \tag{3.13} \end{equation}\] with
\[\begin{equation} p_i^{(n)} = \int_{x_i^{(n)}}^{x_{i+1}^{(n)}}p(x)\text{d}x. \tag{3.14} \end{equation}\]
Actually, the probabilities \(p_i^{(n)}\) will be normalized by \(\int_{-w}^w p(x)\text{d}x\). This is equivalent to discretizing the sample space \(\Omega\) in \(N=2^n\) intervals with \(N+1\) points, so that we can identify the samples \(\omega\) of our discretized random variable with the elements of the set \([N]\). To create the state \(|\psi_n\rangle\) we proceed recursiveliy in \(n\), starting from initial state \(|0\rangle\). To go from \(|\psi_m\rangle = \sum_{i=0}^{2^m-1} \sqrt{p_i^{(m)}}|i\rangle\) to \(|\psi_{m+1}\rangle = \sum_{i=0}^{2^{m+1}-1} \sqrt{p_i^{(m+1)}}|i\rangle\) we proceed by performing a query to an oracle that gives us an angle \(\theta_i\), for \(i \in [2^m]\), which is used to perform the following rotation:
\[\begin{equation} |i\rangle|\theta_i\rangle|0\rangle\mapsto |i\rangle|\theta_i\rangle\left(\cos \theta_i|0\rangle + \sin \theta_i |1\rangle\right), \tag{3.15} \end{equation}\]
In this case, the value \(\theta_i\) is defined as \(\arccos \sqrt{f(i)}\), where the function \(f : [2^m] \mapsto [0,1]\) is defined as:
\[\begin{equation} f(i) = \frac{\int_{x^i_L}^{\frac{x_L^i+x^i_R}{2} } p(x)dx} {\int_{x^i_L}^{x^i_R} p(x)dx}, \tag{3.16} \end{equation}\]
The value of \(f(i)\) is the probability that the \(i\)-th sample \(x^i\) (which lies in the interval \([x^i_L, x^i_R]\)) lines in the leftmost part of this interval (i.e. \([x^i_L, x^i_R+x^i_L/2]\)). After the rotation, we undo the mapping that gives us the \(\theta_i\). These operations resulted in the following state:
\[\begin{equation} \sum_{i=0}^{2^m-1} \sqrt{p_i^{(m)}}|i\rangle\left(\cos \theta_i|0\rangle + \sin \theta_i |1\rangle\right) = |\psi_{m+1}\rangle, \tag{3.17} \end{equation}\]
Computing the mapping for the angles \(\theta_i\) can be done efficiently only for square-integrable probability distributions, i.e. for probability distribution for which the integral in Equation (3.15) can be approximated efficiently. Fortunately, this is the case for most of the probability distribution that we care about.
Creating quantum sample access to a probability distribution is a task often used to obtain quadratic speedups. A recent work (Herbert 2021) pointed out that in certain cases, the time needed to prepare the oracle used to create \(|\psi\rangle\) might cancel the benefits of the speedup. This is the case when we don’t have an analytical formulation for integrals of the form \(\int_a^b p(x)dx\), and we need to resort to numerical methods.
Often in quantum algorithms we want to estimate expected values of integrals of the form \(\mathbb{E}[x] := \int_x x p(x) dx\) (e.g. see Chapter 8), Following a garbage-in-garbage-out argument, (Herbert 2021) was able to show that if we require a precision \(\epsilon\) in \(\mathbb{E}[x]\), we also need to require the same kind of precision for the state preparation of our quantum computer. In particular, in our quantum Monte Carlo algorithms we have to create a state \(|\psi\rangle\) encoding a (discretized) version of \(p(x)\) as \(|\psi\rangle=\sum_{i=0}^{2^n-1} \sqrt{p(i)}|i\rangle\).
Let’s define \(\mu\) as the mean of a probability distribution \(p(x)\) and \(\widehat{\mu}=\mathbb{E(x)}\) be an estimate of \(\mu\). The error of choice for this kind of problem (which comes from applications that we will see in Section 8 ) is called the Root Mean Square Error (RMSE), i.e. \(\widehat{\epsilon} = \sqrt{\mathbb{E}((\widehat{\mu}- \mu)^2)}\). The proof shows that an error of \(\epsilon\) in the first rotation of the GR algorithm, due to an error in the computation of the first \(f(i)\), would propagate in the final error of the expected value of \(\mu\). To avoid this error, we should compute \(f(i)\) with accuracy at least \(\epsilon\). The best classical algorithms allows us to perform this step at a cost of \(O(\frac{1}{\epsilon^2})\), thus canceling the benefits of a quadratic speedup. Mitigating this problem is currently active area of research.
However, if we restrict ourselves to considering loading probabilities from a Gaussian distributions, then we can retain the quadratic speedup of the GR algorithm. This is because when we create quantum sample access to the Gaussian distribution, we must compute integrals of the form
\[\begin{align*} I_{i,m} \left( \sigma \right) = \int_{x_i^{(m)}}^{x_{i+1}^{(m)}}\frac{1}{\sigma\sqrt{\pi}}e^{-x^2/\sigma^2}\text{d}x = \int_{x_i^{(m)}/\sigma}^{x_{i+1}^{(m)}/\sigma}\frac{1}{\sqrt{\pi}}e^{-x^2}\text{d}x \,, \tag{3.18} \end{align*}\]
where the second equality is obtained through the substitution \(x \mapsto \frac{x}{\sigma}\) in the integral, \(m = 1,\, \dots,\, n\) determines the size of the interval partition \(\frac{1}{2^m}\), \(i = 0,\, \dots,\, 2^m\) indexes the interval points, \(\sigma\) is the standard deviation of the Gaussian distribution, and \(w\) determines the end point of the integration, which is chosen such that the interval points \(x_i^{(m)} = w\sigma \left( \frac{i}{2^{m-1}}-1\right)\) is linear in \(\sigma\). By the choice of the interval points, \(I_{i,m} \left(\sigma \right) = I_{i,m} \left( 1 \right)\). Therefore, there is only one set of integrals to be evaluated for all values of \(\sigma\), and we can store the integrals classically to high precision. This iterative construction is thus effective, retaining the quadratic speedup benefits of the GR algorithm.
3.3.2.2 KP-Trees
We now move to discussing the most used technique to load classical data into a quantum computer using ampitude encoding. This technique is the same as the one in the previous section, with the difference that the oracle returning the angles for the controlled rotations are retrived by a quantum memory. In their PhD thesis, Prakash (Prakash 2014) introduced the first procedure to efficiently perform the amplitude encoding of a matrix using a tree-like classical data structure. Given a matrix \(V \in \mathbb{R}^{n \times d}\) the procedure precomputes a data structure with size scaling \(\widetilde{O}(|V|_0)\) and where the time to update the tree with a new entry scales as \(O(\text{poly} \log(nd))\). This technique was called “KP-trees” in (Rebentrost and Lloyd 2018), after the authors (Kerenidis and Prakash) used it in a quantum recommendation system (Kerenidis and Prakash 2017). The proof will make use of the following lemma
Lemma 3.2 (Implementing Rotations with Cascades of Controlled Unitary Gates) Given: a register \(\mathtt{A}\) composed of \(t\) qubits with the binary encoding of the fixed-point representation of a number \(\theta \in (0,2\pi]\), a target qubit \(\mathtt{b}\), and a single qubit rotation parameterized by a single angle \(\mathtt{R}(\theta) \in \mathbb{C}^{2 \times 2}\), then the unitary \[\mathtt{C}_{\mathtt{A}}\mathtt{R}_{\mapsto \mathtt{b}}(\theta) = \prod_{i = 0}^{t-1} \mathtt{C}_i \mathtt{R}_{\mapsto \mathtt{b}}\left( 2^{\lfloor\log_2(\theta)\rfloor-i} \right)\] is equivalent to applying \(\mathtt{R}(\theta)\) on the target qubit if the rotation holds the property \(R(\theta_1 + \theta_2) = R(\theta_1)R(\theta_2)\).
Proof. For a number \(\theta \in (0, 2\pi]\) on \(t\) qubits, the fixed point representation will be of the form \(\mathcal{Q}(a, b, 0):= \mathcal{Q}(z, 0)\), with \(c_1 = \lfloor\log_2(\theta)\rfloor + 1\) and \(c_2 = t - c_1\). \ The application of \(\mathtt{C}_{\mathtt{A}}\mathtt{R}_{\mapsto \mathtt{b}}(\theta)\) is equivalent to \(t\) single qubit application of \(\mathtt{R}(\theta)\) on the target qubit \(\mathtt{b}\), with the identity on all other qubits, where the angles have to be adjusted. %with parameters \(z_i2^{\lfloor\log(\theta)\rfloor-i}\). In particular: \[\begin{equation*} \prod_{i = 0}^{t-1} \mathtt{C}_i \mathtt{R}_{\mapsto \mathtt{b}}\left( 2^{\lfloor\log_2(\theta)\rfloor-i} \right) = \prod_{i = 0}^{t-1} \mathtt{R}_{\mapsto \mathtt{b}}\left( z_i 2^{\lfloor\log_2(\theta)\rfloor-i} \right) \end{equation*}\] where \(z_i \in \{ 0,1 \}\) is the state of qubit \(i\) and we have omitted the tensor product with the identity on all other qubits of register \(\mathtt{A}\) for simplicity. Then: \[\begin{equation*} \prod_{i = 0}^{t-1} \mathtt{R}_{\mapsto \mathtt{b}}\left( z_i 2^{\lfloor\log_2(\theta)\rfloor-i} \right) = R_{\mapsto \mathtt{b}}\left( \sum_{i=0}^{t-1} z_i 2^{\lfloor\log_2(\theta)\rfloor-i} \right) = R_{\mapsto \mathtt{b}}(\theta), \end{equation*}\] where we have used that \(R(\phi_1 + \phi_2) = R(\phi_1)R(\phi_2)\) and observing that \(\sum\limits_{i=0}^{t-1} z_i2^{\lfloor\log(\theta)\rfloor-i}\) is the fixed-point encoding of \(\theta\).\ Since the proof only makes use of the fact that the parameterized gate needs to have the property \(R_n(\phi_1 + \phi_2) = R_n(\phi_1)R_n(\phi_2)\), we can easily extend it to the Phase gate \(P\) and the y rotation gate \(R_y\).
Exercise 3.7 Prove that \(\sigma_y(\theta + \phi) = \sigma_y(\theta)\sigma_y(\phi)\) for the \(\sigma_y\) rotation given by
\[\begin{equation} \sigma_y(\theta) = \begin{pmatrix} \cos(\frac{\theta}{2})& -\sin(\frac{\theta}{2})\\ \sin(\frac{\theta}{2}) & \cos(\frac{\theta}{2}) \end{pmatrix} \end{equation}\]
Prove the same property for the phase gate \(P(\theta + \phi) = P(\theta)P(\phi)\) defined by
\[\begin{equation} P(\theta) = \begin{pmatrix} 1 & 0\\ 0 & e^{i \theta} \end{pmatrix} \end{equation}\]
The original work developed a procedure to perform the amplitude encoding of a matrix \(V \in \mathbb{R}^{n \times d}\) with KP-trees in 2 steps: a pre-processing step and circuit implementation. In the data pre-processing step, for each row \(v_i \in \mathbb{R}^{n}\), which is composed of elements \(v_{ij} \in \mathbb{R}\), a binary tree is created where the leaves contain the values \(v_{ij}^2\) and the sign of \(v_{ij}\). Each intermediate node contains the sum of the leaves of the sub tree rooted at that node. The circuit implementation makes use of the \(\mathsf{QMD}\) to access the next layer of the desired tree \(v_i\) until the leaves are reach.
Here we’ll present an optimized version of KP-trees for state preparation of complex matrices. In this version each tree is pruned such that it only saves the angles that are required for the state preparation rather than the partial norms, which halves the size of the memory. Furthermore, we clearly lay out the circuits for the implementation of the state preparation, which can be seen in 3.7. In addition the complex matrices are handled by storing the phase of each complex number. The circuit implementation of the phase makes use of a circuit as depicted in figures 3.8.
Theorem 3.12 (Optimized KP-trees for complex vectors) Let \(V \in \mathbb{C}^{n \times d}\), where we assume that \(n\) and \(d\) are powers of \(2\), then there is a data structure to store the rows of \(V\) such that:
- The size of the data structure is \(O(\|V\|_0 \log^2(nd))\).
- The time to insert, update or delete a single entry \(v_{ij}\) is \(O(\log^{2}(nd))\).
- A quantum algorithm that has quantum access to the data structure can perform the mapping \(\tilde{U}: |i\rangle|0\rangle \rightarrow |i\rangle|V_i\rangle\) for \(i \in [m]\), corresponding to the rows of the matrix currently stored in memory and the mapping \(\tilde{V}: |0\rangle|j\rangle \rightarrow |\tilde{V}\rangle|j\rangle\), for \(j \in [n]\), where \(\tilde{V} \in \mathbb{R}^{m}\) has entries \(\tilde{V}_i = ||V_i||\), in time \((2+t)\log(nd) + 2t\), where \(t\) is the precision of the result.
Proof. The data structure is composed of \(n+1\) binary trees, one for each row of the matrix, and an additional one for the vector of norms of the rows. For the \(i^{th}\) row of \(V\)(i.e. \(V_i\)) we build the binary tree \(B_i\). Given that that \(d\) is a power of 2, there will be \(\log(d)\) layers to a tree \(B_i\).
For an incoming element \(j\) of the vector \(V_i\) of the form \(v_{ij}e^{i\theta_{ij}}\), the \(j^{\text{th}}\) leaf of the \(i^{th}\) tree will store the tuple \((v_{ij}^2, \theta_{ij})\). Once a leaf is updated, the internal nodes will also be updated such that an internal node \(l\) will store the sum of the moduli \(v_{ij}\) of the leaves of a sub tree rooted at \(l\). This procedure continues until all the matrix is loaded.
At the end of the procedure, we represent an internal node \(l\) in the \(i^{th}\) tree at depth \(d\) as \(B_{id}^{l}\). If \(j_b\) represents the \(b^{th}\) bit of \(j\) then:
\[\begin{equation} B_{id}^{l} = \sum\limits_{\substack{j_1,...,j_d=l\\j_{d+1},...,j_{\log(n)} \in \{0,1\}}} v_{ij}^2, \end{equation}\]
This implies that the first \(d\) bits of \(j\) written in binary are fixed to \(l\), indicating that we are at depth \(d\). This procedure requires \(O (\log^2(nd))\) time.
After the tree has been filled it will be pruned. The pruning involves changing the values in the internal nodes such that they store the angle required to perform the state preparation. This will allow to remove \(v_{ij}^2\) from the leaves which will now only store the phases \({\theta_{ij}}\).
Given a node \(B_{id}^{l}\), the pruned tree will have nodes given by:
\[\begin{equation} B_{i,d}^{' l} = \begin{cases} 2\arccos \left( \sqrt{\frac{B_{i,d+1}^{2l}}{B_{i,d}^{l}}}\right), & \text{if } d < \log(n)\\ \theta_{i,\log(n)}^l, & \text{if } d=\log(n) \end{cases}, \end{equation}\]
The size of the data structure scales as \(O(|V|_0\log^2(nd))\).
Since the first \(\log(n)-1\) layers are concerned with preparing the real amplitudes, \(B_{i,k}^{' l} \in [0, \pi]\) for \(k \in [\log(n)-1]\), whilst the last layer will be bounded by \(B_{i,\log(n)}^{' l} \in [0, 2\pi]\). Each angle in the tree will be stored in its fixed-point representation. Since the first \(\log(n)-1\) layers are concerned with preparing the real amplitudes, \(B_{i,k}^{' l} \in [0, \pi]\) for \(k \in [\log(n)-1]\) meaning their fixed-point representation \(\mathcal{Q(z)}\) will have \(c_1 = 1\) and \(c_2 = t\) for some precision \(t\). The last layer contains the phases which are bounded by \(B_{i,\log(n)}^{' l} \in [0, 2\pi]\), meaning their fixed-point representation \(\mathcal{Q(z)}\) will have \(c_1 = 2\) and \(c_2 = t-1\) for some precision \(t\) . This means that for some precision \(t\) the address register will require \(t'=t+1\) qubits.
The circuit will require quantum access to the data structure \(B_{i,d}^{'}\) as well as 3 registers: an index register \(|i\rangle\) which contains \(\lceil \log(i) \rceil\) qubits and the binary representation of \(i\); a \(t'\)-qubit address(angle) register which will load the fixed-point representation of the angles up to a precision \(t\); and the main register composed of \(\log(n)\) qubits.
A quantum query to the data structure will load from \(B_{i}^{'}\) the fixed-point representation of the angle on the address register which will be followed by a cascade of controlled rotations, as seen in lemma ??, in order to produce the next layer of the data structure \(B_{i}\). Given the first \(k\) qubits of the register being in a state \(\Psi_k\), then the action on the \(k+1\) qubit be as follows:
\[\begin{equation} |i\rangle|0\rangle^{\otimes t'}|\Psi_k\rangle|0\rangle \xrightarrow{\text{QMD}} |i\rangle|B_{i,d}^{'}\rangle|\Psi_k\rangle|0\rangle\xrightarrow{\sigma_y(B_{i,d}^{'})} |i\rangle|B_{i,d}^{'}\rangle|\Psi_k\rangle\frac{1}{\sqrt{B_{i,d}^{l}}}\left(\sqrt{B_{i,d+1}^{2l}}|0\rangle + \sqrt{B_{i,d+1}^{2l+1}}|1\rangle\right), \end{equation}\]
Where \(\xrightarrow{\sigma_y(B_{i,k}^{'})}\) indicates a cascade of \(\sigma_y\) rotations controlled on the address register and targeted on the \(k+1\) qubit of the main register.
Repeating this procedure for the first \(n-1\) layers of the tree \(B_i^{'}\) will leave the main register in the state \(|\Psi_{\log(n)}\rangle\), i.e. the amplitude encoding of the moduli of the vector \(V_i\). The addition of the phases will require a quantum query to the classical data structure to access the final layer of the binary tree. Following the query, a cascade of phase gates on the \(\log(n)^{th}\) qubit is performed. This is followed by a \(\sigma_x\) gate and then another cascade of phase rotations and finally another \(\sigma_x\) gate. The \(\sigma_x\) gate is required since the phase gates only acts on the state where the last bit is a \(1\). The transformation will then be:
\[\begin{equation} |i\rangle|0\rangle^{\otimes t'}|\Psi_{\log(n)}\rangle \xrightarrow{\text{QMD}} |i\rangle|B_{i,\log(n)}^{'}\rangle|\Psi_{\log(n)}\rangle\xrightarrow{\text{CP}(B_{i,\log(n)}^{'})} |i\rangle|B_{i,\log(n)}^{'}\rangle e^{i\theta_{il}}|\Psi_{\log(n)}\rangle, \end{equation}\]
Where \(\theta_{il}\) is the phase saved in the leaf \(l\). From this we can see that performing \(\tilde{U}: |i\rangle|0\rangle \rightarrow |i\rangle|V_i\rangle\) for \(i \in [m]\) requires \(2\log(n) + 2\) queries to the classical data structure. In addition, a precision of \(t\) will require at most \(t'(\log(n) + 2)\) controlled rotations.
The final tree is for the implementation of \(\tilde{V}: |0\rangle|j\rangle \rightarrow |\tilde{V}\rangle|j\rangle\), for \(j \in [n]\). As before we construct the tree such the leaves store \(||V_i||^2\) and an internal node \(l\) stores the entries of the subtree rooted at \(l\). It is important to note that in this case the node does not need to store the phases since we are interesting in the moduli of the rows, which halves the dimension of this tree. Following an analogous procedure of pruning, a circuit of controlled \(\sigma_y\) rotations will grant the application of the unitary \(\tilde{V}\) to the main register.
Figure 3.7: A section of the circuit for state preparation with pruned KP-trees. For a vector \(V_i \in \mathbb{C}^{n}\) we require 3 register: an index register \(|i\rangle\); a \(t\)-qubit address register which will load the angles up to a precision \(t\); and the main register composed of \(\log(n)\) qubits. At a intermediate step of the procedure the main register will hold a state which represents the \(k\)-th layer of the KP-tree \(\Psi_k\) and the aim of the circuit will be to prepare the \(k+1\) layer of the tree, \(\Psi_{k+1}\). This starts with a quantum query to the data structure which loads the angles to the address register. This is followed by a cascade of controlled rotations and finally an inverse call to the data structure. Repeating this circuit \(\log(n)\) times produces the state \(\Psi_{\log(n)}\) which is a vector which hold the moduli of the components of \(V_i\). In total the circuit will have a depth of \(t\log(n)\) and will require \(2\log(n)\) queries to the data structure.
Figure 3.8: The circuit that adds the phase in state preparation with pruned KP-trees. This starts with a quantum query to the data structure which loads the angles to the address register, which is followed by a cascade of phase rotation, a NOT gate and another cascade. The requirmenet of 2 cascades is that the controlled phase rotations only acts on the quantum states with a \(1\) as the last bit. The application of this circuit produces the desired vector \(V_i\).
We now show an example of the state preparation with pruned KP-trees of a vector of size 4. Figure 3.9 shows the difference between an original KP-tree and a pruned version, whilst 3.10 shows the full circuit implementation to load the vector.
Example 3.1 As a worked example we will take a \(4\) element vector for which we will construct a data structure and then, using a \(\mathsf{QMD}\), we will load it into a quantum circuit. The vector is:
\[\begin{equation} V^{T} = \left( 0.4e^{i\frac{\pi}{4}}, 0.4e^{i\frac{\pi}{12}} , 0.8e^{i\frac{\pi}{3}}, 0.2e^{i\frac{\pi}{6}} \right), \end{equation}\]
In particular our aim is to produce the state:
\[\begin{equation} |\phi\rangle = 0.4e^{i\frac{\pi}{4}}|00\rangle + 0.4e^{i\frac{\pi}{12}}|01\rangle + 0.8e^{i\frac{\pi}{3}}|10\rangle + 0.2e^{i\frac{\pi}{6}}|11\rangle, \end{equation}\]
The first step is the construction of the data structure. Figure 3.9 shows the initial tree and the pruned tree. The difference between the two is that the initial tree stores the partial norms of the entries, whilst the pruned tree stores the angles required to implement the partial norms as \(\sigma_y\) rotations.
Since we are working with a vector we will only have 1 qubit in the index register which will be set to the state \(|0\rangle\). The angle will be stored with a precision of \(t\) which we will assume is a large number. This will require the angle(address) register to be composed of \(t\) qubits. Finally, since the vector has 4 elements, we will require 2 qubits in the main register.
An initial call to the \(\mathsf{QMD}\) will load the angle on the address register, this will be followed by a cascade of \(\sigma_y\) rotations on the first qubit and an inverse call to the \(\mathsf{QMD}\) to remove the angle from the address register. This will produce the state:
\[\begin{equation} |0\rangle|0\rangle^{\otimes t}\left( \sqrt{0.32}|0\rangle + \sqrt{0.68}|1\rangle\right)|0\rangle, \end{equation}\]
A similar process is done is the second step where in this case the call to the \(\mathsf{QMD}\) is made using the index register and the first qubit and will access the second row of the pruned KP-tree. This will be followed by a similar cascade of \(\sigma_y\) rotations on the second qubit of the main register and inverse call to the \(\mathsf{QMD}\) to remove the angle from the address register. This will produce the state:
\[\begin{equation} |0\rangle|0\rangle^{\otimes t}\left(\sqrt{0.32}|0\rangle \left( \sqrt{\frac{0.16}{0.32}}|0\rangle + \sqrt{\frac{0.16}{0.32}}|1\rangle \right) + \sqrt{0.68}|1\rangle \left( \sqrt{\frac{0.64}{0.68}}|0\rangle + \sqrt{\frac{0.2}{0.68}}|1\rangle \right)\right), \end{equation}\]
\[\begin{equation} = |0\rangle|0\rangle^{\otimes t}\left(0.4|00\rangle + 0.4|01\rangle + 0.8|10\rangle + 0.2|11\rangle\right), \end{equation}\]
Now we need to add the phases. As already seen, this will be done with a query to the \(\mathsf{QMD}\) to access the final row of the pruned KP-tree, then a cascade of phase rotations \(P\). This will produce the state:
\[\begin{equation} |0\rangle|\theta\rangle\left(0.4|00\rangle + 0.4e^{i\frac{\pi}{12}}|01\rangle + 0.8|10\rangle + 0.2e^{i\frac{\pi}{6}}|11\rangle\right), \end{equation}\]
Where the state \(|\theta\rangle\) is some superposition containing the binary representation of all the leaves of the pruned KP-tree. Because the nature of the phase gate, a \(\sigma_x\) gate followed by another cascade of phase rotations is required to load the remaining phases. Finally, a \(\sigma_x\) gate and a inverse query to the \(\mathsf{QMD}\) will produce the desired state!
\[\begin{equation} |0\rangle|0\rangle^{\otimes t} \left(0.4e^{i\frac{\pi}{4}}|00\rangle + 0.4e^{i\frac{\pi}{12}}|01\rangle + 0.8e^{i\frac{\pi}{3}}|10\rangle + e^{i\frac{\pi}{6}}0.2|11\rangle\right), \end{equation}\]
The full circuit for this can be seen in the figure 3.10.
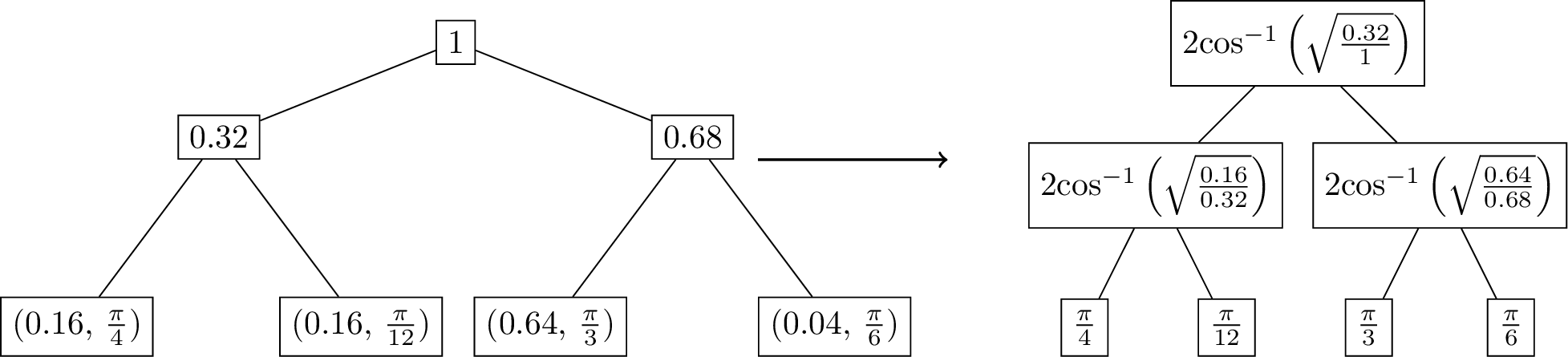
Figure 3.9: The original and pruned tree used for the example. The difference between the two is that the initial tree stores the partial norms of the vector entries, whilst the pruned tree only stores the angles required to implement the required \(\sigma_y\) and phase rotations.
Figure 3.10: The circuit to perform state preparation of the vector reported in the worked example. An initial call to the \(\mathsf{QMD}\) loads the angle on the address register, which is followed by a cascade of \(\sigma_y\) rotations on the first qubit and an inverse call to the \(\mathsf{QMD}\) to remove the angle from the address register. A similar process is done for the second step where the call to the \(\mathsf{QMD}\) is made using the index register and the first qubit and will access the first layer of the pruned KP-tree. This will be followed by a similar cascade of \(\sigma_y\) rotations on the second qubit of the main register and inverse call to the \(\mathsf{QMD}\). The final step requires adding the phases. This will be done with a query to the \(\mathsf{QMD}\) to access the final row of the pruned KP-tree, then a cascade of phase rotation \(P\). Because the nature of the phase gate, a \(\sigma_x\) gate followed by another cascade of phase rotations is required to load the remaining phases. Finally, a \(\sigma_x\) gate and a inverse query to the \(\mathsf{QMD}\) will produce the amplitude encoding.
The following exercise might be helpful to clarify the relation between quantum query access to a vector and quantum sampling access.
Exercise 3.8 Suppose you have quantum access to a vector \(x = [x_1, \dots, x_N]\), where each \(x_i \in [0,1]\). What is the cost of creating quantum sampling access to \(x\), i.e. the cost of preparing the state \(\frac{1}{Z}\sum_{i=1}^N x_i |i\rangle\). Hint: query the state in superposition and perform a controlled rotation. Can you improve the cost using amplitude amplification? What if \(x_i \in [0, B]\) for a \(B > 1\)?
Lower bounds in query complexity can be used to prove that the worst case for performing state preparation with the technique used in the exercise (i.e. without KP-trees/quantum sampling access) are \(O(\sqrt{N})\).
3.3.3 Block encoding
We first turn our attention to creating block encodings from oracles doing amplitude encoding. In the following, we use the shortcut notation to define the matrix \(A^{(p)}\) to be a matrix where each entry \(A^{(p)}_{ij} = (A_{ij})^p\).
Exercise 3.9 Let \(X \in \mathbb{R}^{n \times d}\). Suppose you have access to \(U_R\) and \(U_L\) defined as:
- \(U_R|i\rangle|0\rangle = |i\rangle|x_i\rangle = |i\rangle \sum_{j} (x_i)_j |j\rangle\);
- \(U_L|0\rangle|i\rangle = |\widetilde{x}\rangle|i\rangle\) where \(\widetilde{x}\) is the vector of the norms of the rows of the matrix \(x\).
Using once \(U_R\) and \(U_L\), build a unitary \(U_X\) that performs the mapping \(|0\rangle \mapsto \frac{1}{\|X\|_F}\sum_{i,j}x_{ij} |i,j\rangle\).
Theorem 3.13 (Creation of state matrix) Assume to have the unitaries \(U_L\) and \(U_R\) for a matrix \(X \in \mathbb{R}^{n \times n}\). Then \(U_R^\dagger U_L\) is a \((\|X\|_F, 0)\)-block encoding of \(X\).
Proof. Define the matrix \(P \in \mathbb{R}^{nm}\) by the column vectors \(|i\rangle|x_i\rangle\) for \(i \in [m]\), and the matrix \(Q\) by \(Q \in \mathbb{R}^{nn \times nn}\) defined by the column vectors \(|\overline{x}\rangle|i\rangle\). One can verify that \[(P^\dagger Q)_{ij} = \langle i, x_i|\overline{x}, j\rangle = \frac{X_{ij}}{\|X\|_F}. \] To conclude the proof, it suffices to recall the definition of block encoding: \[ \|X - \|X\|_F(\langle 0| \otimes I)U_R^\dagger U_L (|0\rangle \otimes I) \| = \|X - \|X\|_F P^\dagger Q \| = 0. \]
Definition 3.14 (Possible parameterization of μ for the KP-trees) For \(s_{p}(A) = \max_{i \in [n]} \sum_{j \in [d]} A_{ij}^{p}\), we chose \(\mu_p(A)\) to be:
\[\begin{equation} \mu_p(A)=\min_{p\in [0,1]} (\left\lVert A\right\rVert_{F}, \sqrt{s_{2p}(A)s_{(1-2p)}(A^{T})}). \end{equation}\]
Lemma 3.3 (Block encodings from quantum data structures (Chakraborty, Gilyén, and Jeffery 2019)) Let \(A\in\mathbb{C}^{M\times N}\), and \(\overline{A}\in\mathbb{C}^{(M+N)\times (M+N)}\) be the symmetrized matrix defined as:
\[\begin{equation} \overline{A}=\left[\begin{array}{cc}0 & A\\ A^\dagger & 0 \end{array}\right]. \end{equation}\]
Fix \(p\in [0,1]\). If \(A\in\mathbb{C}^{M\times N}\), and \(A^{(p)}\) and \((A^{(1-p)})^\dagger\) are both stored in quantum-accessible data structures with sufficient precision, then there exist unitaries \(U_R\) and \(U_L\) that can be implemented in time \(O\left(polylog(MN/\epsilon)\right)\) such that \(U_R^\dagger U_L\) is a \((\mu_p(A),\lceil\log (N+M+1)\rceil,\epsilon)\)-block encoding of \(\overline{A}\).
On the other hand, if \(A\) is stored in a quantum-accessible data structure with sufficient precision, then there exist unitaries \(U_R\) and \(U_L\) that can be implemented in time \(O(polylog(MN)/\epsilon)\) such that \(U_R^\dagger U_L\) is a \((\|A\|_F,\lceil\log(M+N)\rceil,\epsilon)\)-block encoding of \(\overline{A}\).
The second point of the previous theorem is equivalent to what we saw in Section 3.3.2.2.
3.3.3.1 Block encoding from sparse access
Using this we can then see how to perform a block encoding. We start by reporting this result from (Gilyén et al. 2019).
Theorem 3.14 (Block-Encoding from sparse access (Gilyén et al. 2019)) Let \(A \in \mathbb{C}^{2^w \times 2^w}\) be a matrix that is \(s_r\)-row-sparse and \(s_c\)-column-sparse, and each element of \(A\) has absolute value at most \(1\). Suppose that we have access to the following sparse access oracles acting on two \((w+1)\) qubit registers:
\[\begin{equation} O_r: |i\rangle|k\rangle \mapsto |i\rangle|r_{ik}\rangle \forall i \in [2^w] - 1, k \in [s_r], \text{and} \end{equation}\]
\[\begin{equation} O_c: |l\rangle|j\rangle \mapsto |c_lj\rangle|j\rangle \forall l \in [s_c], j \in [2^w]-1, \text{where} \end{equation}\]
\(r_{ij}\) is the index of the \(j\)-th non-zero entry of the \(i\)-th row of \(A\), or if there are less than \(i\) non-zero entries, than it is \(j+2^w\), and similarly \(c_ij\) is the index for the \(i\)-th non-zero entry of the \(j-th\) column of \(A\), or if there are less than \(j\) non-zero entries, than it is \(i+2^w\). Additionally assume that we have access to an oracle \(O_A\) that returns the entries of \(A\) in binary description:
\[\begin{equation} O_A : |i\rangle|j\rangle|0\rangle^{\otimes b} \mapsto |i\rangle|j\rangle|a_{ij}\rangle \forall i,j \in [2^w]-1 \text{where} \end{equation}\]
\(a_{ij}\) is a \(b\)-bit description of the \(ij\)-matrix element of \(A\). Then we can implement a \((\sqrt{s_rs_c}, w+3, \epsilon)\)-block encoding of \(A\) with a single use of \(O_r\), \(O_c\), two uses of \(O_A\) and additionally using \(O(w + \log^{2.5}(\frac{s_rs_c}{\epsilon}))\) one and two qubit gates while using \(O(b,\log^{2.5}\frac{s_rs_c}{\epsilon})\) ancilla qubits.
The previous theorems can be read more simply as: “under reasonable assumptions (quantum general graph model for rows and for columns - see previous section), we can build \((\sqrt{s_rs_c}, w+3, \epsilon)\)-block encodings of matrices \(A\) with circuit complexity of \(O(\log^{2.5}(\frac{s_rs_c}{\epsilon}))\) gates and constant queries to the oracles”.
The interested reader can read Yang et al. (2024) to learn how to create block encodings from sparse access.
3.4 Use case: working with classical probability distributions
We have \(4\) ways of working with classical probability distributions in a quantum computer (Gur, Hsieh, and Subramanian 2021):
- Purified query access
- Sample access
- Query access to a frequency vector of a distribution
- Drawing samples classically and perform some computation on a quantum computer
Let’s start with a formal definition of the frequency vector model. This is a kind of query access, but since it is used only for probability distrubtions we decided to include it in this section.
Definition 3.15 (Quantum query access to a probability distribution in the frequency vector model) Let \(p=(p_1, p_2, \dots p_n)\) be a probability distribution on \(\{1, 2, \dots, n\}\), and let \(n\geq S \in \mathbb{N}\) be such that there is a set of indices \(S_i \subseteq [S]\) for which \(p_i = \frac{\left|S_i\right|}{S}.\) We have quantum access to a probability distribution in the frequency vector model if there is an quantum oracle that, for \(\forall s \in [S_i]\) performs the mapping \(O_p |s\rangle \mapsto |s\rangle|i\rangle\).
Exercise 3.10 Given a matrix \(M := \sum\limits_{j=0}^{n-1} a_{j}U_{j}\), which is a linear combination of unitary matrices \(U_j\), consider the unitary transformation
\[\begin{equation} U_M = (U_{\text{PREP}}^{\dagger} \otimes I) U_{\text{SEL}} ( U_{\text{PREP}} \otimes I) \end{equation}\]
where \(U_{\text{PREP}}|0\rangle = |a\rangle = \sum\limits_{j=0}^{n-1} a_{j}|j\rangle\) and \(U_{\text{SEL}} = \sum\limits_{j=0}^{n-1} |j\rangle\langle j| \otimes U_{j}\). Then show that \(U_M\) is a block encoding of \(M\):
\[\begin{equation} \left(\langle 0|\otimes I \right) U_M \left(|0\rangle\otimes I \right) = M = |a_j|^2 \sum\limits_{j=0}^{n-1} b_{j}U_{j} \end{equation}\]
3.5 Retrieving Data
In order to retrieve information from a quantum computer, we are going to use some efficient procedures that allow to reconstruct classically the information stored in a quantum state. These procedures can be thought of as ways of sampling from a pure state \(|x\rangle\). The idea for an efficient quantum tomography is that we want to minimize the number of times that the state \(|x\rangle\) is created.
Most of the quantum algorithms discussed here will work with pure quantum states. We assume to have access to the unitary that creates the quantum state that we would like to retrieve, and that we have access to the unitary that creates the state (and that we can control it). Under these conditions, the process of performing tomography is greatly simplified. According to the different error guarantees that we require, we can chose among two procedures.
Theorem 3.15 (Vector state tomography with L2 guarantees (Kerenidis and Prakash 2018)) Given access to unitary \(U\) such that \(U|0\rangle = |x\rangle\) and its controlled version, there is a tomography algorithm with calls \(U\) and its controlled version for \(\frac{ d \log d }{\epsilon^{2}})\) times, that produces a unit vector \(\widetilde{x} \in \mathbb{R}^{d}\) such that \(\left\lVert\widetilde{x} - |x\rangle \right\rVert_{2} \leq \epsilon\) with probability at least \((1-1/poly(d))\).
Theorem 3.16 (Vector state tomography with L∞ guarantees (Kerenidis, Landman, and Prakash 2019)) Given access to unitary \(U\) such that \(U|0\rangle = |x\rangle\) and its controlled version, there is a tomography algorithm with calls \(U\) and its controlled version \(\frac{ \log d }{\epsilon^{2}})\) that produces a unit vector \(\widetilde{x} \in \mathbb{R}^{d}\) such that \(\left\lVert\widetilde{x} - |x\rangle \right\rVert_{\ell_\infty} \leq \epsilon\) with probability at least \((1-1/poly(d))\).
Note that in both kinds of tomography the dependence on the error in the denominator is quadratic, and this is because of the Hoeffding inequality. Another remark on the hypothesis of the algorithms for tomography is that they require a unitary \(U\) such that \(U|0\rangle\mapsto|x\rangle\) for the \(|x\rangle\) in question. Often times, due to the random error in the quantum subroutines used inside the algorithms, this state \(|x\rangle\) might slightly change every time.
Exercise 3.11 Can you obtain \(\ell_2\) tomography with error \(\epsilon\) on a \(d\) dimensional state if you have have only access to an algorithm that perform \(\ell_\infty\) tomography with error \(\epsilon^\ast\) on the same state? (I.e. what should you set the value of \(\epsilon^{\ast}\)?).
Exercise 3.12 Consider Theorem 3.15 and Theorem 3.16. What is the sample complexity of a tomography algorithm returning error in norm \(\ell_p\)? In other words, find the sample complexity to return a vector such that \(\left\lVert\widetilde{x} - |x\rangle \right\rVert_{\ell_p} \leq \epsilon\) with probability at least \((1-1/poly(d))\).
3.5.1 Density matrices
Much of the current literature in quantum tomography is directed towards reconstructing a classical description of density matrices. This problem is considerably harder than reconstructing a pure state.
Theorem 3.17 (Efficient quantum tomography (O’Donnell and Wright 2016)) An unknown rank-r mixed state \(\rho \in \mathbb{C}^{d \times d}\) can be estimated to error \(\epsilon\) in Frobenius distance using \(n = O(d/\epsilon^2)\) copies, or to error \(\epsilon\) in trace distance using \(n=O(rd/\epsilon^2)\) copies.
Different techniques have been recently developed in (K. Zhang et al. 2020). There, the authors used the assumption on doing tomography on a state \(|x\rangle\) that is in the row space of a rank \(r\) matrix \(A\) for which we have quantum access. They propose an algorithm to obtain the classical description of the coefficients \(x_i\) in the base spanned by the rows \(\{A_{i}\}_{i=0}^r\)of \(A\), so that \(|x\rangle = \sum_i^r x_i |A_i\rangle\). This requires \(\tilde O(poly(r))\) copies of the output states and \(\tilde{O}(poly(r), \kappa^r)\) queries to input oracles. While this procedure has the benefit of not being linear in the output dimension of the final state, the high dependence on the rank might hide the advantages compared to the previous quantum tomography procedures. For completeness, the result is as follows.
Theorem 3.18 (Improved quantum tomography (K. Zhang et al. 2020)) For the state \(|v\rangle\) lies in the row space of a matrix \(A \in \mathbb{R}^{n \times d}\) with rank \(r\) and condition number \(\kappa(A)\), the classical form of \(|v\rangle\) can be obtained by using \(O(r^3\epsilon^2)\) queries to the state \(|v\rangle\), \(O(r^{11}\kappa^{5r}\epsilon^{-2}\log(1/\delta))\) queries to \(\mathsf{QRAM}\) oracles of \(A\) and \(O(r^2)\) additional inner product operations between rows, such that the \(\ell_2\) norm error is bounded in \(\epsilon\) with probability at least \(1-\delta\).